$ systemctl status blackbox_exporter
blackbox_exporter.service - Blackbox Exporter
Loaded: loaded (/etc/systemd/system/blackbox_exporter.service; disabled; vendor preset: enabled)
Active: active (running) since Wed 2019-05-08 00:02:40 UTC; 5s ago
Main PID: 10084 (blackbox_export)
Tasks: 6 (limit: 4704)
CGroup: /system.slice/blackbox_exporter.service
└─10084 /usr/local/bin/blackbox_exporter --config.file /etc/blackbox_exporter/blackbox.yml
May 08 00:02:40 ip-172-31-41-126 systemd[1]: Started Blackbox Exporter.
May 08 00:02:40 ip-172-31-41-126 blackbox_exporter[10084]: level=info ts=2019-05-08T00:02:40.5229204Z caller=main.go:213 msg="Starting blackbox_exporter" version="(version=0.14.0, branch=HEAD, revision=bb
May 08 00:02:40 ip-172-31-41-126 blackbox_exporter[10084]: level=info ts=2019-05-08T00:02:40.52553523Z caller=main.go:226 msg="Loaded config file"
May 08 00:02:40 ip-172-31-41-126 blackbox_exporter[10084]: level=info ts=2019-05-08T00:02:40.525695324Z caller=main.go:330 msg="Listening on address" address=:9115
Enable the service on boot:
1
$ systemctl enable blackbox_exporter
Configure Prometheus
Next, we need to provide context to prometheus on what to monitor. We will inform prometheus to monitor a web endpoint on port 8080 using the blackbox exporter (we will create a python simplehttpserver to run on port 8080).
Edit the prometheus config /etc/prometheus/prometheus.yml and append the following:
To install a blackbox exporter dashboard: https://grafana.com/dashboards/7587, create a new dashboard, select import, provide the ID: 7587, select the prometheus datasource and select save.
The dashboard should look similar to this:
Next up, Alertmanager
In the next tutorial we will setup Alertmanager to alert when our endpoint goes down
So we are pushing our time series metrics into prometheus, and now we would like to alarm based on certain metric dimensions. That’s where alertmanager fits in. We can setup targets and rules, once rules for our targets does not match, we can alarm to destinations suchs as slack, email etc.
What we will be doing:
In our previous tutorial we installed blackbox exporter to probe a endpoint. Now we will install Alertmanager and configure an alert to notify us via email and slack when our endpoint goes down. See this post if you have not seen the previous tutorial.
So when we get alerted, our alert will include a link to our alert. We need to provide the base url of that alert. That get’s done in our alertmanager systemd unit file: /etc/systemd/system/alertmanager.service under --web.external-url passing the alertmanager base ip address:
Then we need to do the same with the prometheus systemd unit file: /etc/systemd/system/prometheus.service under --web.external-url passing the prometheus base ip address:
Inspect the status of alertmanager and prometheus:
12
$ systemctl status alertmanager
$ systemctl status prometheus
If everything seems good, enable alertmanager on boot:
1
$ systemctl enable alertmanager
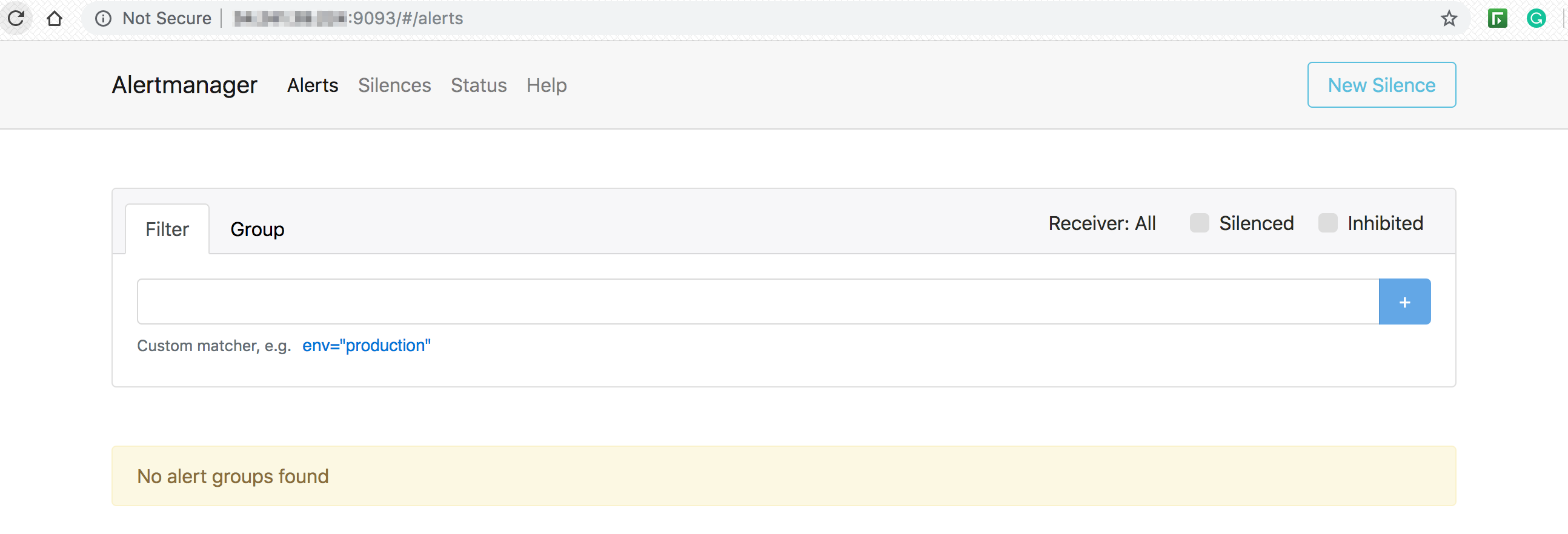
Access Alertmanager:
Access alertmanager on your endpoint on port 9093:
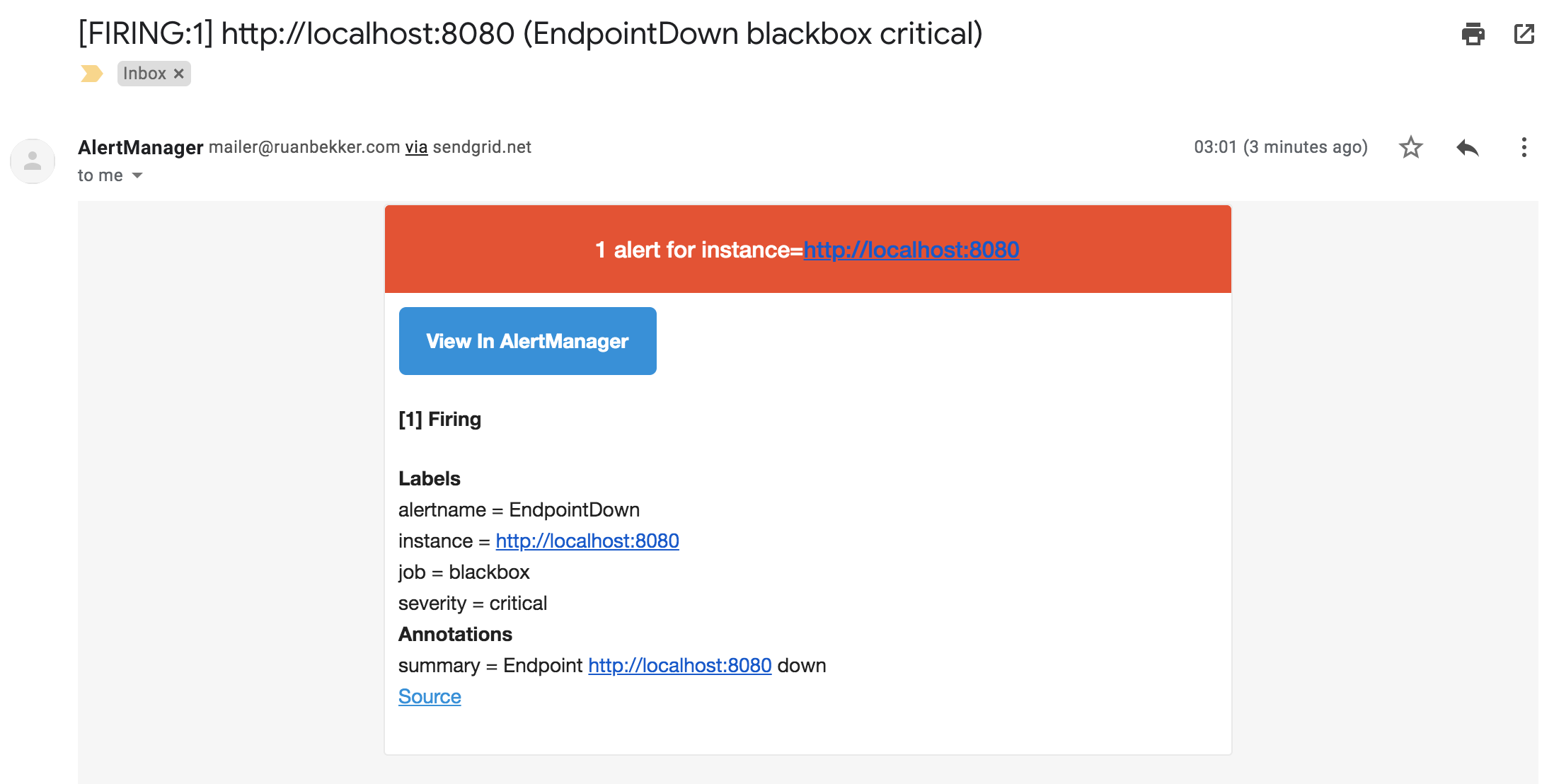
From our previous tutorial we started a local web service on port 8080 that is being monitored by prometheus. Let’s stop that service to test out the alerting. You should get a notification via email:
And the notification via slack:
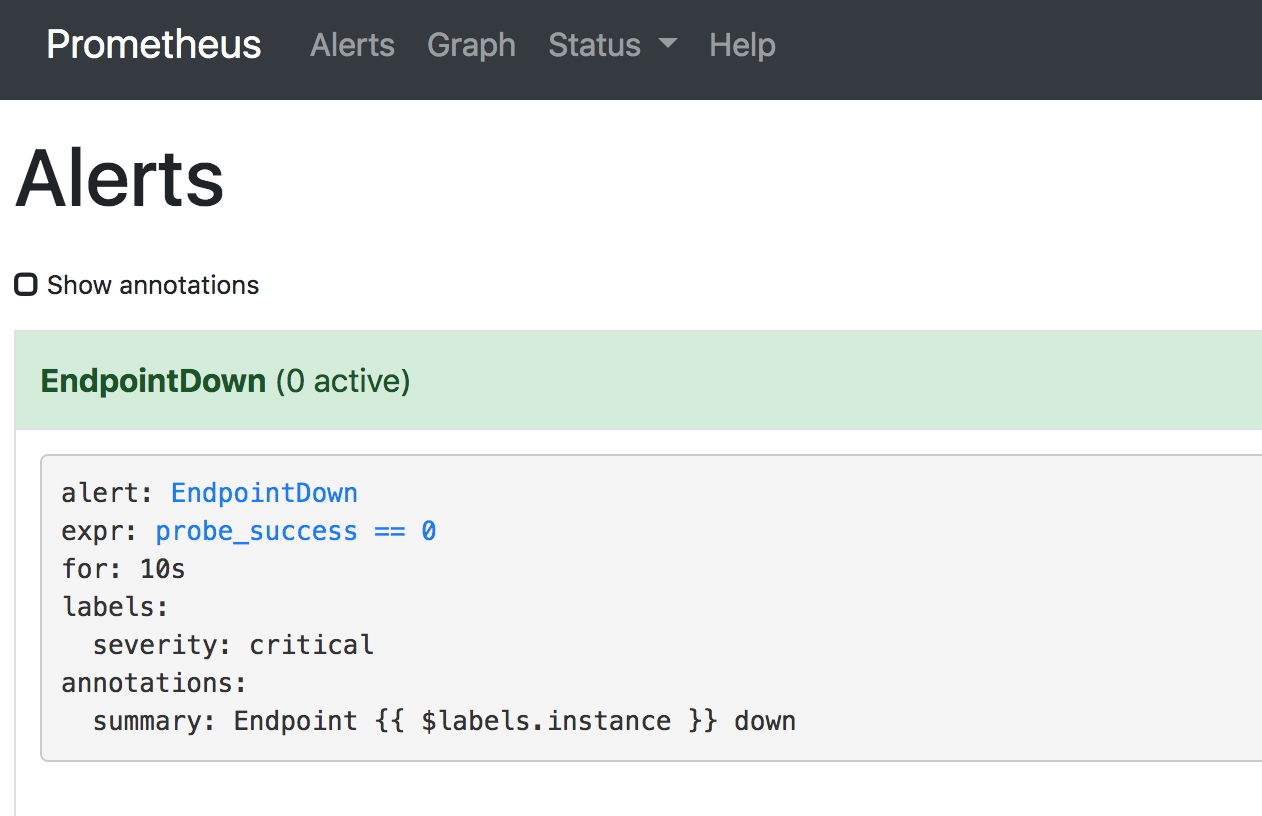
When you start the service again and head over to the prometheus ui under alerts, you will see that the service recovered:
Install Prometheus Alertmanager Plugin
Install the Prometheus Alertmanager Plugin in Grafana. Head to the instance where grafana is installed and install the plugin:
Install the dasboard grafana.com/dashboards/8010. Create a new datasource, select the prometheus-alertmanager datasource, configure and save.
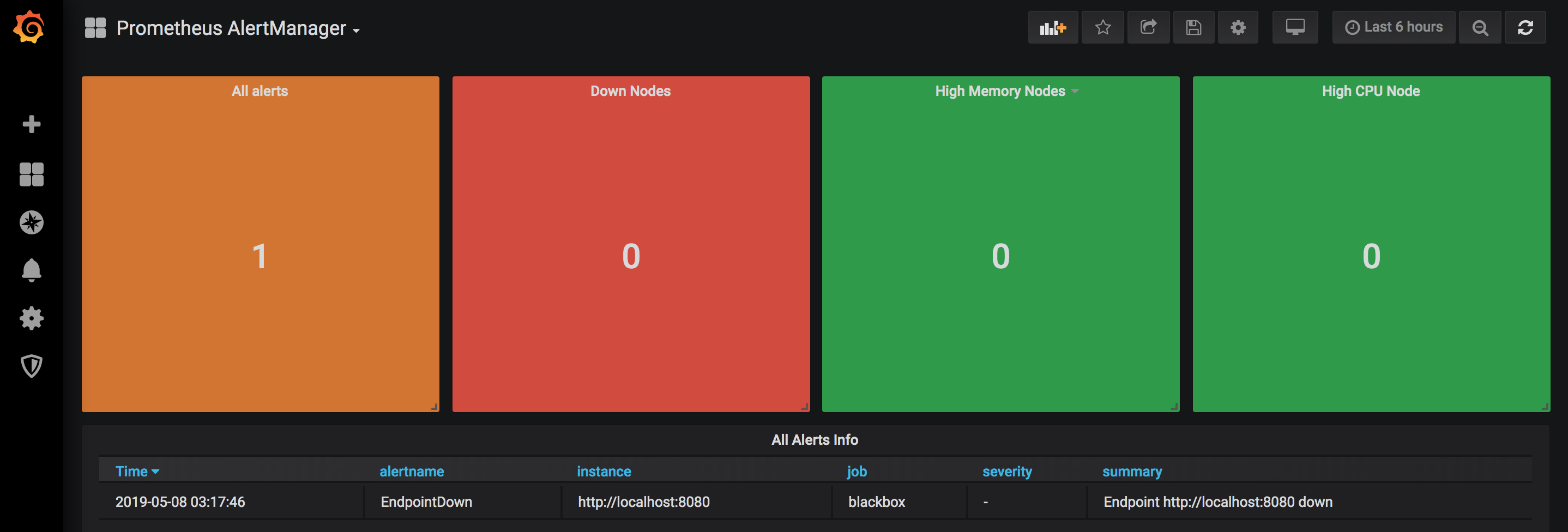
Add a new dasboard, select import and provide the ID 8010, select the prometheus-alertmanager datasource and save. You should see the following (more or less):
Grafana is a Open Source Dashboarding service that allows you to monitor, analyze and graph metrics from datasources such as prometheus, influxdb, elasticsearch, aws cloudwatch, and many more.
Not only is grafana amazing, its super pretty!
Example of how a dashboard might look like:
What are we doing today
In this tutorial we will setup grafana on linux. If you have not set up prometheus, follow this blogpost to install prometheus.
Install Grafana
I will be demonstrating how to install grafana on debian, if you have another operating system, head over to grafana documentation for other supported operating systems.
In most cases when we want to scrape a node for metrics, we will install node-exporter on a host and configure prometheus to scrape the configured node to consume metric data. But in certain cases we want to push custom metrics to prometheus. In such cases, we can make use of pushgateway.
Pushgateway allows you to push custom metrics to push gateway’s endpoint, then we configure prometheus to scrape push gateway to consume the exposed metrics into prometheus.
Pre-Requirements
If you have not set up Prometheus, head over to this blogpost to set up prometheus on Linux.
What we will do?
In this tutorial, we will setup pushgateway on linux and after pushgateway has been setup, we will push some custom metrics to pushgateway and configure prometheus to scrape metrics from pushgateway.
Install Pushgateway
Get the latest version of pushgateway from prometheus.io, then download and extract:
12
$ wget https://github.com/prometheus/pushgateway/releases/download/v0.8.0/pushgateway-0.8.0.linux-amd64.tar.gz
$ tar -xvf pushgateway-0.8.0.linux-amd64.tar.gz
$ systemctl status pushgateway
pushgateway.service - Pushgateway
Loaded: loaded (/etc/systemd/system/pushgateway.service; disabled; vendor preset: enabled)
Active: active (running) since Tue 2019-05-07 09:05:57 UTC; 2min 33s ago
Main PID: 6974 (pushgateway)
Tasks: 6 (limit: 4704)
CGroup: /system.slice/pushgateway.service
└─6974 /usr/local/bin/pushgateway --web.listen-address=:9091 --web.telemetry-path=/metrics --persistence.file=/tmp/metric.store --persistence.interval=5m --log.level=info --log.format=logger:st
May 07 09:05:57 ip-172-31-41-126 systemd[1]: Started Pushgateway.
Configure Prometheus
Now we want to configure prometheus to scrape pushgateway for metrics, then the scraped metrics will be injected into prometheus’s time series database:
At the moment, I have prometheus, node-exporter and pushgateway on the same node so I will provide my complete prometheus configuration, If you are just looking for the pushgateway config, it will be the last line:
With this method, you can push any custom metrics (bash, lambda function, etc) to pushgateway and allow prometheus to consume that data into it’s time series database.
In this post we will setup a highly available mysql galera cluster on docker swarm.
About
The service is based of docker-mariadb-cluster repository and it’s designed not to have any persistent data attached to the service, but rely on the “nodes” to replicate the data.
Note, that however this proof of concept works, I always recommend to use a remote mysql database outside your cluster, such as RDS etc.
Since we don’t persist any data on the mysql cluster, I have associated a dbclient service that will run continious backups, which we will persist the path where the backups reside to disk.
The dbclient is configured to be in the same network as the cluster so it can reach the mysql service. The default behavior is that it will make a backup every hour (3600 seconds) to the /data/{date}/ path.
Deploy the stack:
12345
$ docker stack deploy -c docker-compose.yml galeraCreating network dbnetCreating service galera_dbclusterCreating service galera_dblbCreating service galera_dbclient
Have a look to see if all the services is running:
At the moment we only have 1 replica for our mysql cluster, let’s go ahead and scale the cluster to 3 replicas:
1234567
$ docker service scale galera_dbcluster=3galera_dbcluster scaled to 3overall progress:3 out of 3 tasks1/3:running [==================================================>]2/3:running [==================================================>]3/3:running [==================================================>]verify:Service converged
$ docker exec -it $(docker ps -f name=galera_dbclient -q) mysql -uroot -ppassword -h dblb -e'select * from mydb.foo;'+------+| name |+------+| ruan |+------+
Simulate a Node Failure:
Simulate a node failure by killing one of the mysql containers:
1
$ docker kill 9e336032ab52
Verify that one container is missing from our service:
123
$ docker service lsID NAME MODE REPLICAS IMAGE PORTSp8kcr5y7szte galera_dbcluster replicated 2/3 toughiq/mariadb-cluster:latest
While the container is provisioning, as we have 2 out of 3 running containers, read the data 3 times so test that the round robin queries dont hit the affected container (the dblb wont route traffic to the affected container):
1234567891011121314151617181920
$ docker exec -it $(docker ps -f name=galera_dbclient -q) mysql -uroot -ppassword -h dblb -e'select * from mydb.foo;'+------+| name |+------+| ruan |+------+$ docker exec -it $(docker ps -f name=galera_dbclient -q) mysql -uroot -ppassword -h dblb -e'select * from mydb.foo;'+------+| name |+------+| ruan |+------+$ docker exec -it $(docker ps -f name=galera_dbclient -q) mysql -uroot -ppassword -h dblb -e'select * from mydb.foo;'+------+| name |+------+| ruan |+------+
Verify that the 3rd container has checked in:
123
$ docker service lsID NAME MODE REPLICAS IMAGE PORTSp8kcr5y7szte galera_dbcluster replicated 3/3 toughiq/mariadb-cluster:latest
How to Restore?
I’m deleting the database to simulate the scenario where we need to restore:
Vault’s transit secrets engine handles cryptographic functions on data-in-transit. Vault doesn’t store the data sent to the secrets engine, so it can also be viewed as encryption as a service.
In this tutorial we will demonstrate how to use Vault’s Transit Secret Engine.
Prometheus is one of those awesome open source monitoring services that I simply cannot live without. Prometheus is a Time Series Database that collects metrics from services using it’s exporters functionality. Prometheus has its own query language called PromQL and makes graphing epic visualiztions with services such as Grafana a breeze.
What are we doing today
We will install the prometheus service and set up node_exporter to consume node related metrics such as cpu, memory, io etc that will be scraped by the exporter configuration on prometheus, which then gets pushed into prometheus’s time series database. Which can then be used by services such as Grafana to visualize the data.
Other exporters is also available, such as: haproxy_exporter, blackbox_exporter etc, then you also get pushgateway which is used to push data to, and then your exporter configuration scrapes the data from the pushgateway endpoint. In a later tutorial, we will set up push gateway as well.
Install Prometheus
First, let’s provision our dedicated system users for prometheus and node exporter:
We need to tell prometheus to scrape itself in order to get prometheus performance data, edit the prometheus configuration:
1
$ vim /etc/prometheus/prometheus.yml
And add a scrape config: Set the interval on when it needs to scrap, the job name which will be in your metric and the endpoint which it needs to scrape:
Let’s look at the status to see if everything works as expected:
1234567891011
$ systemctl status prometheus
prometheus.service - Prometheus
Loaded: loaded (/etc/systemd/system/prometheus.service; disabled; vendor preset: enabled)
Active: active (running) since Tue 2019-03-26 11:59:10 UTC; 6s ago
Main PID: 16374 (prometheus)
Tasks: 9 (limit: 4704)
CGroup: /system.slice/prometheus.service
└─16374 /usr/local/bin/prometheus --config.file /etc/prometheus/prometheus.yml --storage.tsdb.path /var/lib/prometheus/ --web.console.templates=/etc/prometheus/consoles --web.console.libraries=
...
Mar 26 11:59:10 ip-172-31-41-126 prometheus[16374]: level=info ts=2019-03-26T11:59:10.893770598Z caller=main.go:655 msg="TSDB started"
Seems legit! Enable the service on startup:
1
$ systemctl enable prometheus
Install Node Exporter
Now since we have prometheus up and running, we can start adding exporters to publish data into our prometheus time series database. As mentioned before, with node exporter, we will allow prometheus to scrape the node exporter endpoint to consume metrics about the node:
You will find the latest version from their website, which I have added at the top of this post.
$ node_exporter.service - Node Exporter
Loaded: loaded (/etc/systemd/system/node_exporter.service; disabled; vendor preset: enabled)
Active: active (running) since Tue 2019-03-26 12:01:39 UTC; 5s ago
Main PID: 16474 (node_exporter)
Tasks: 4 (limit: 4704)
CGroup: /system.slice/node_exporter.service
└─16474 /usr/local/bin/node_exporter
...
Mar 26 12:01:39 ip-172-31-41-126 node_exporter[16474]: time="2019-03-26T12:01:39Z" level=info msg="Listening on :9100" source="node_exporter.go:111"
If everything looks good, enable the service on boot:
1
$ systemctl enable node_exporter
Configure Node Exporter
Now that we have node exporter running, we need to tell prometheus how to scrape node exporter, so that the node related metrics can end up into prometheus. Edit the prometheus config:
1
$ vim /etc/prometheus/prometheus.yml
I’m providing the full config, but the config is the last section, where you can see the jobname is node_exporter:
Once the config is saved, restart prometheus and have a look at the status if everything is going as expected:
12
$ systemctl restart prometheus
$ systemctl status prometheus
Nginx Reverse Proxy
Let’s add a layer of security and front our setup with a nginx reverse proxy, so that we don’t have to access prometheus on high ports and we have the option to enable basic http authentication. Install nginx:
1
$ apt install nginx apache2-utils -y
Create the authentication file:
1
$ htpasswd -c /etc/nginx/.htpasswd admin
Create the nginx site configuration, this will tel nginx to route connections on port 80, to reverse proxy to localhost, port 9090, if authenticated:
12
$ rm /etc/nginx/sites-enabled/default
$ vim /etc/nginx/sites-enabled/prometheus.conf
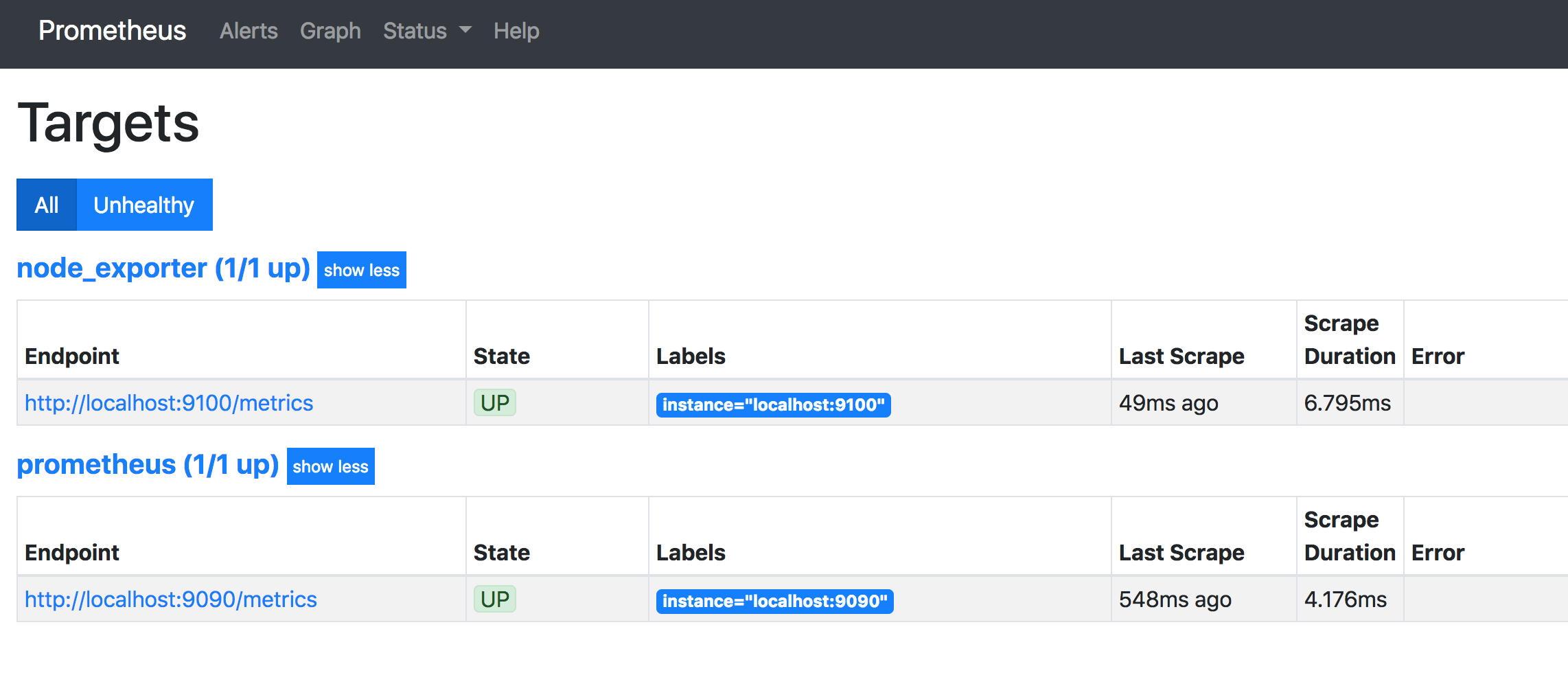
Once you have authenticated, head over to status, here you will see status info such as your targets, this wil be the endpoints that prometheus is scraping:
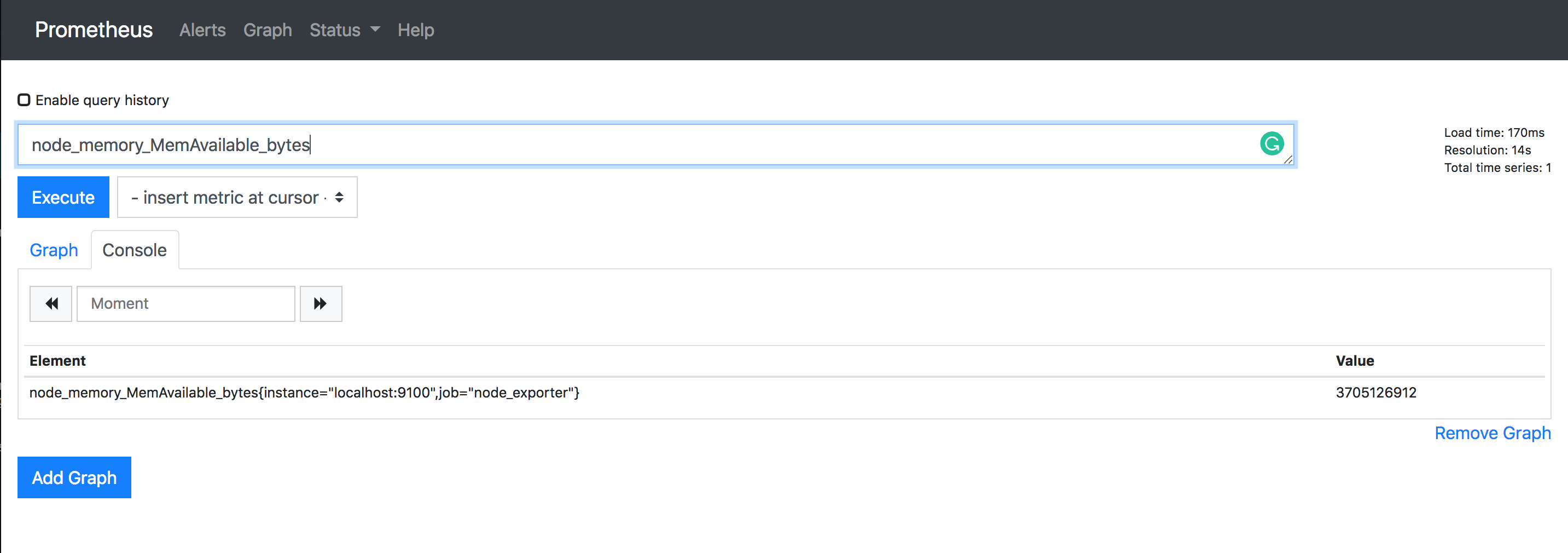
For the first query, we want to see the available memory of this node in bytes (node_memory_MemAvailable_bytes):
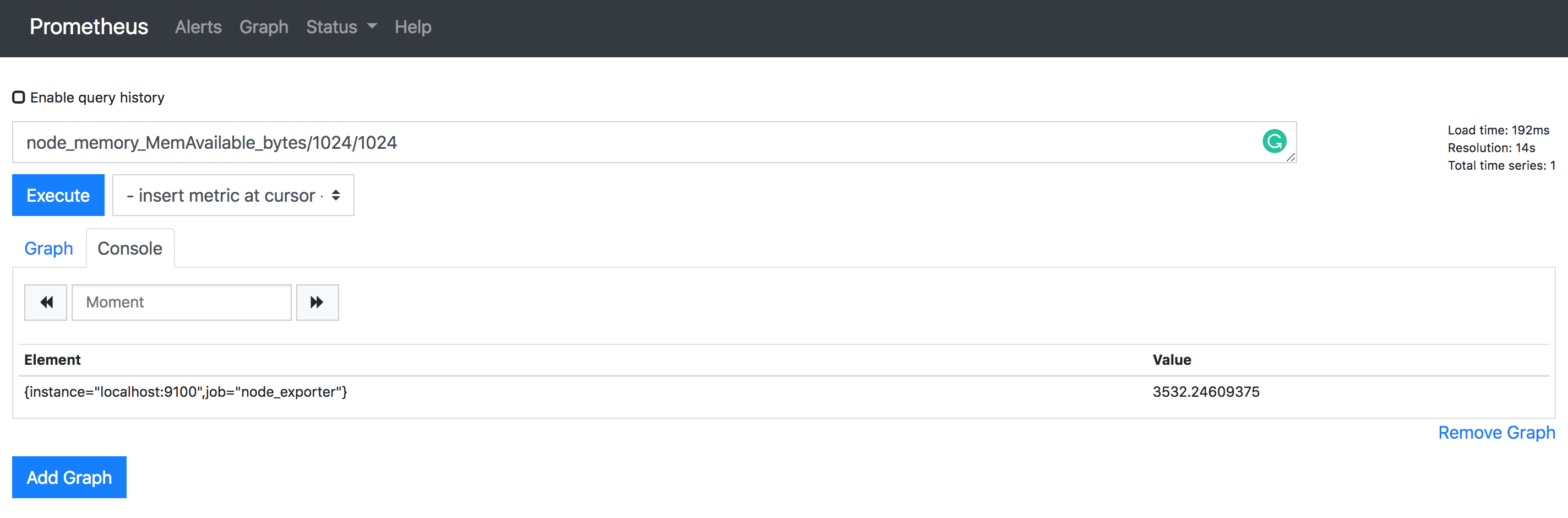
Now since the value is in bytes, let’s convert the value to MB, (node_memory_MemAvailable_bytes/1024/1024)
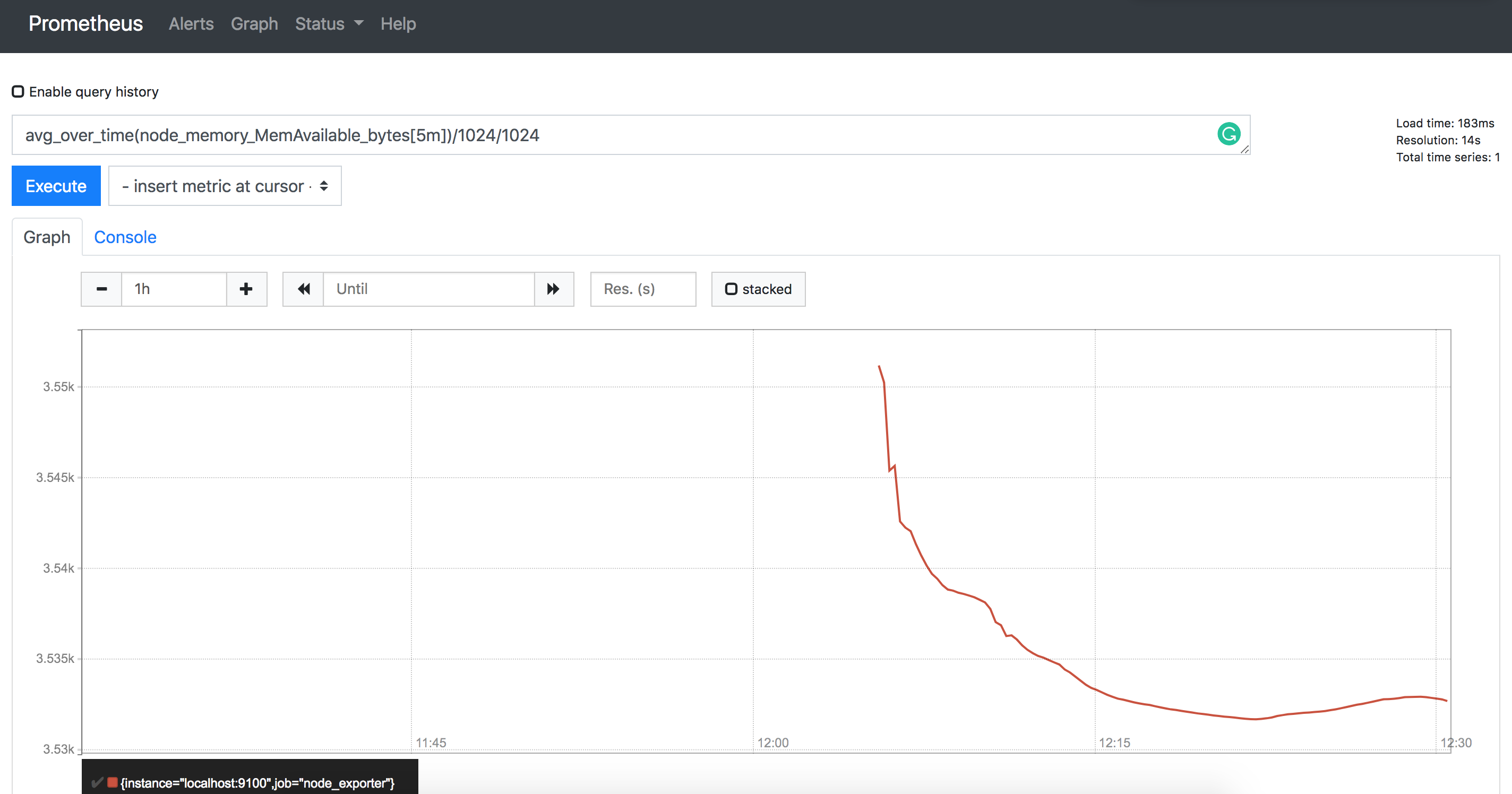
Let’s say we want to see the average memory available in 5 minute buckets:
That’s a few basic ones, but feel free to checkout my Prometheus Cheatsheet for other examples. I update them as I find more queries.
Thanks
Hope this was informative. I am planning to publish a post on visualizing prometheus data with Grafana (which is EPIC!) and installing Pushgateway for custom integrations.
I was trying to install grafana on ubuntu when I got faced with: “the following signatures couldn’t be verified because the public key is not available” error as seen below:
1234567891011
$ sudo add-apt-repository "deb https://packages.grafana.com/oss/deb stable main"
Hit:1 http://eu-west-1.ec2.archive.ubuntu.com/ubuntu bionic InRelease
Get:2 http://eu-west-1.ec2.archive.ubuntu.com/ubuntu bionic-updates InRelease [88.7 kB]
Get:3 http://eu-west-1.ec2.archive.ubuntu.com/ubuntu bionic-backports InRelease [74.6 kB]
Get:4 http://security.ubuntu.com/ubuntu bionic-security InRelease [88.7 kB]
Get:5 http://eu-west-1.ec2.archive.ubuntu.com/ubuntu bionic-backports/universe Sources [2068 B]
Get:6 http://eu-west-1.ec2.archive.ubuntu.com/ubuntu bionic-backports/universe amd64 Packages [3492 B]
Get:7 https://packages.grafana.com/oss/deb stable InRelease [12.1 kB]
Err:7 https://packages.grafana.com/oss/deb stable InRelease
The following signatures couldn't be verified because the public key is not available: NO_PUBKEY 8C8C34C524098CB6
Reading package lists... Done
In order to continue, we need to import the trusted key:
12345
$ apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 8C8C34C524098CB6
Executing: /tmp/apt-key-gpghome.9xlwQh2M06/gpg.1.sh --keyserver keyserver.ubuntu.com --recv-keys 8C8C34C524098CB6
gpg: key 8C8C34C524098CB6: public key "Grafana <info@grafana.com>" imported
gpg: Total number processed: 1
gpg: imported: 1
Now that the key has been imported, we can update and continue: