Vault is one of Hashicorp’s awesome services, which enables you to centrally store, access and distribute dynamic secrets such as tokens, passwords, certificates and encryption keys.
What will we be doing today
We will setup a Vault Server on Docker and demonstrate a getting started guide with the Vault CLI to Initialize the Vault, Create / Use and Manage Secrets.
Populate the vault config vault.json. (As you can see the config is local, in the next couple of posts, I will show how to persist this config to Amazon S3)
I will demonstrate how to use the Vault CLI to interact with Vault. Let’s start by installing the vault cli tools, I am using mac, so I will be using brew:
1
$ brew install vault
Set environment variables:
1
$ export VAULT_ADDR='http://127.0.0.1:8200'
Initialize the Vault Cluster:
Initialize new vault cluster with 6 key shares:
1234567891011121314151617181920
$ vault operator init -key-shares=6 -key-threshold=3
Unseal Key 1: RntjR...DQv
Unseal Key 2: 7E1bG...0LL+
Unseal Key 3: AEuhl...A1NO
Unseal Key 4: bZU76...FMGl
Unseal Key 5: DmEjY...n7Hk
Unseal Key 6: pC4pK...XbKb
Initial Root Token: s.F0JGq..98s2U
Vault initialized with 10 key shares and a key threshold of 3. Please
securely distribute the key shares printed above. When the Vault is re-sealed,
restarted, or stopped, you must supply at least 3 of these keys to unseal it
before it can start servicing requests.
Vault does not store the generated master key. Without at least 3 key to
reconstruct the master key, Vault will remain permanently sealed!
It is possible to generate new unseal keys, provided you have a quorum of
existing unseal keys shares. See "vault operator rekey" for more information.
In order to unseal the vault cluster, we need to supply it with 3 key shares:
$ vault login s.tdlEqsfzGbePVlke5hTpr9Um
Success! You are now authenticated. The token information displayed below
is already stored in the token helper. You do NOT need to run "vault login"
again. Future Vault requests will automatically use this token.
Using the cli your auth token will be saved locally at ~/.vault-token.
Enable the secret kv engine:
1
$ vault secrets enable -version=1 -path=secret kv
Create and Read Secrets
Write a secret to the path enabled above:
1
$ vault kv put secret/my-app/password password=123
List your secrets:
1234
$ vault kv list secret/
Keys
----
my-app/
Read the secret (defaults in table format):
12345
$ vault kv get secret/my-app/password
Key Value
--- -----
refresh_interval 768h
password 123
Write a secret appname to our key: secret/fooapp/appname:
1234567
$ vault kv put secret/fooapp/appname appname=app1
Key Value
--- -----
created_time 2019-04-07T12:36:41.7577102Z
deletion_time n/a
destroyed false
version 1
Overwrite the key with a couple of requests:
12
$ vault kv put secret/fooapp/appname appname=app2
$ vault kv put secret/fooapp/appname appname=app3
Read the current value:
12
$ vault kv get -field=appname secret/fooapp/appname
app3
Get the version=2 value of this file:
12
$ vault kv get -field=appname -version=2 secret/fooapp/appname
app2
Thanks
Thanks for reading, hope this was informative. Have a look at Hashicorp’s Vault Documentation for more information on the project. I will post more posts on Vault under the #vault category.
The first step of our deploy will invoke a shell script that will establish a ssh tunnel to the docker host, mounting the docker socket to a tcp local port, then exporting the docker host port to the tunneled port, ci/scripts/deploy.sh:
Another nice thing about Drone CI is the “Services” configuration within your pipeline. At times your unit or integration testing steps might be dependent of a database such as MongoDB, MySQL etc.
Drone allows you to spin up a ephemeral database service such as MongoDB using a Docker container as the fist step within your pipeline, defined in the services section. This step will always run first.
The service container will be reachable via the configured container name as its hostname. Keep note that if you run multiple paralel jobs that the service container will only be reachable from the container where the mongodb container is running.
What are we doing today
We will setup a really basic (and a bit useless) pipeline that will spin up a mongodb service container, use a step to write random data to mongodb and a step that reads data from mongodb.
For demonstration purposes, the data is really random but more focused on the service section.
All the source code for this demonstration is available on my github repository
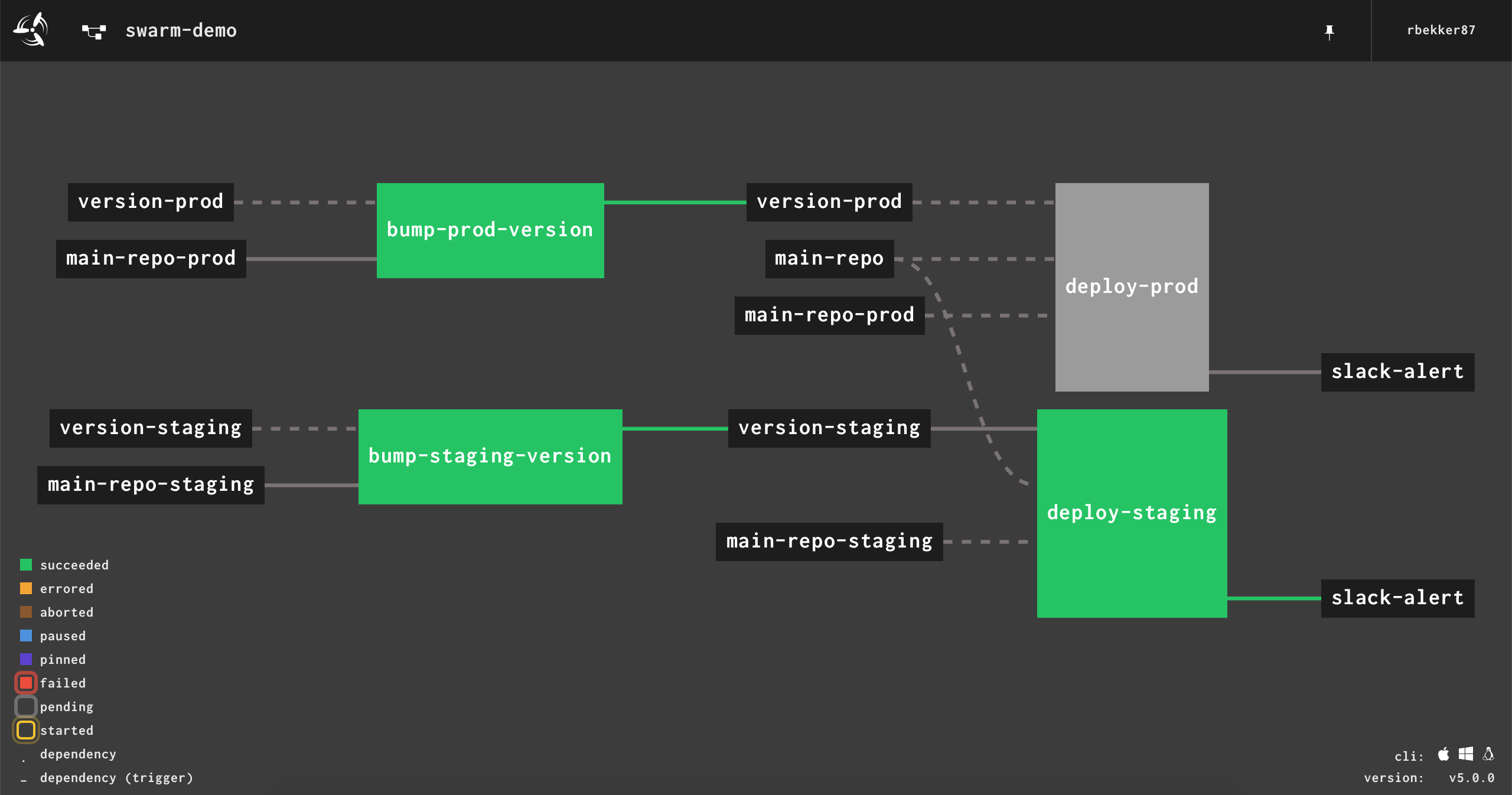
Our Drone Pipeline
First we define our service, mongodb. Once the mongodb service is running, we will have our build step, our step that runs the mongodb version against our database, write data into our mongodb database, then read the data from mongodb, then the last step running a shell command with the date.
---kind:pipelinename:mongotestsservices:-name:mongoimage:mongo:4command:[--smallfiles]ports:-27017steps:-name:build-stepimage:alpinecommands:-echo "this should be a step that does something"-name:mongodb-return-versionimage:mongo:4commands:-date-mongo --host mongo --eval "db.version()"-name:mongodb-test-writesimage:mongo:4commands:-date-sh scripts/write_mongo.sh-name:mongodb-test-readsimage:mongo:4commands:-date-sh scripts/read_mongo.sh-name:last-stepimage:alpinecommands:-echo "completed at $(date)"
Our scripts referenced in our steps:
The first will be our script that write random data into mongodb, scripts/write_mongo.sh:
Once your source code is set in github, enable the repository on drone and push to github to trigger the build.
Demo and Screenshots
After pushing to github to trigger the build, heading over to drone, I can see that mongodb is running and our step has completed that executes the db.version() against mongodb:
Next our step executes to write the random data into mongodb:
After the data has been written to mongodb, our next step will read the number of documents from mongodb, and also run a query for transaction prices more than 990:
Once that has completed, we will have a shell command returning the time when the last step completed:
Some time ago, I assisted a customer who was trying to do a select count(*) via beeline and failed with:
123
[hadoop@ip-10-10-9-226 ~]$ beeline -u jdbc:hive2://nn-emr.sysint.dxone.local:10000/default --silent=true --outputformat=csv2 -e "select count(*) from basetables_rms.rms_site"
19/04/26 06:41:15 [main]: WARN jdbc.HiveConnection: Request to set autoCommit to false; Hive does not support autoCommit=false.
Error: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.tez.TezTask (state=08S01,code=1)
When reproducing this I found a jira: https://issues.apache.org/jira/browse/HIVE-14631 which related to the same issue and the workaround was to switch your execution engine to mapreduce. By doing that, it worked, but wanted a better resolution for the customer.
Debugging:
When setting enabling debugging, I found that the error is related to permissions:
12345678
$ beeline -u jdbc:hive2://172.31.31.247:10000/default --silent=false --outputformat=csv2 -e "select count(*) from testdb.users"
Connecting to jdbc:hive2://172.31.31.247:10000/default
Connected to: Apache Hive (version 2.1.1-amzn-0)
Driver: Hive JDBC (version 2.1.1-amzn-0)
19/04/26 10:24:01 [main]: WARN jdbc.HiveConnection: Request to set autoCommit to false; Hive does not support autoCommit=false.
...
ERROR : Failed to execute tez graph.
org.apache.hadoop.security.AccessControlException: Permission denied: user=anonymous, access=WRITE, inode="/user/anonymous":hdfs:hadoop:drwxr-xr-x
So it seems that when the client (anonymous) is trying to copy the hive execution jar to is home path in HDFS, in this case (/home/anonymous/.hiveJars/) it fails due to permissions.
Resolution:
By passing the hadoop user, I was able to get the expected results:
123456
$ beeline -n hadoop -u jdbc:hive2://172.31.31.247:10000/default --silent=false --outputformat=csv2 -e "select count(*) from testdb.users"
INFO : Completed executing command(queryId=hive_20190426103246_33253d86-3ebc-462f-a5a1-f01877dd00a8); Time taken: 17.08 seconds
INFO : OK
c0
1
1 row selected (17.282 seconds)
* Whenever a push to master is receive on github, the pipeline will be triggered
* The content from our github repository will be cloned to the agent on a container
* Jekyll will build and the output will be transferred to docker swarm using rsync
* The docker-compose.yml will be transferred to the docker swarm host using scp
* A docker stack deploy is ran via ssh
Install Jekyll Locally
Install Jekyll locally, as we will use it to create the initial site. I am using a mac, so I will be using brew. For other operating systems, have a look at this post.
I will be demonstrating with a weightloss blog as an example.
Install jekyll:
1
$ brew install jekyll
Go ahead and create a new site which will host the data for your jekyll site:
1
$ jekyll new blog-weightloss
Create a Github Repository
First we need to create an empty github repository, in my example it was github.com/ruanbekker/blog-weightloss.git. Once you create the repo change into the directory created by the jekyll new command:
1
$ cd blog-weightloss
Now initialize git, set the remote, add the jekyll data and push to github:
You should see your data on your github repository.
Create Secrets on Drone
Logon to the Drone UI, sync repositories, activate the new repository and head over to settings where you will find the secrets section.
Add the following secrets:
12345678
Secret Name: swarm_host
Secret Value: ip address of your swarm
Secret Name: swarm_key
Secret Value: contents of your private ssh key
Secret Name: swarm_user
Secret Value: the user that is allowed to ssh
You should see the following:
Add the Drone Config
Drone looks from a .drone.yml file in the root directory for instructions on how to do its tasks. Lets go ahead and declare our pipeline:
If you want to be notified about your builds, you can add a slack notification step as the last step.
To do that, create a new webhook integration, you can follow this post for a step by step guide. After you have the webhook, go to secrets and create a slack_webhook secret.
Now we need to push our .drone.yml and docker-compose.yml to github. Since the repository is activated on drone, any push to master will trigger the pipeline, so after this push we should go to drone to look at our pipeline running.
As you head over to your drone ui, you should see your pipeline output which will look more or less like this (just look how pretty it is! :D )
Test Jekyll
If your deployment has completed you should be able to access your application on the configured domain. A screenshot of my response when accessing Jekyll:
---
title: "My First Post"
date: 2019-04-23T09:39:23+02:00
description: This is an introduction post to showcase Hugo.
slug: hello-world-my-first-post
categories:
- hugo
- blog
tags:
- helloworld
- hugo
- blog
draft: false
---

Hello world and welcome to my first post
## New Beginning
This is a new beginning on my blog on hugo and this seems pretty cool so im adding random text here because I dont know **what** to add here. So im adding a lot more random text here.
This is another test.
## Code
This is python code:
from random import randint
from faker import Fake
randint(1, 2)
destFile = "largedataset-" + timestart + ".txt"
file_object = open(destFile,"a")
file_object.write("uuid" + "," + "username" + "," + "name" + "," + "country" + "\n")
def create_names(fake):
for x in range(numberRuns):
genUname = fake.slug()
genName = fake.first_name()
genCountry = fake.country()
file_object.write(genUname + "," + genName + "," + genCountry + "\n")
..
This is bash code:
#!/usr/bin/env bash
var="ruan"
echo "Hello, ${var}"
## Tweets
This is one of my tweets, see [configuration](https://gohugo.io/content-management/shortcodes/#highlight) for more shortcodes:
## Tables
This is a table:
|**id** |**name**|**surname**|**age**| **city** |
|----------|--------|-----------|-------|--------------|
|20-1232091|ruan |bekker |32 |cape town |
|20-2531020|stefan |bester |32 |kroonstad |
|20-4835056|michael |le roux |35 |port elizabeth|
## Lists
This is a list:
* one
* two
* [three](https://example.com)
This is another list:
1. one
2. two
3. [three](https://example.com)
## Images
This is an embedded photo:

Run the Server
You can set the flags in your main config as well. Go ahead and run the server:
12345
$ hugo server \
--baseURL "http://localhost/" \
--themesDir=themes --theme=pickles \
--bind=0.0.0.0 --port=8080 --appendPort=true \
--buildDrafts --watch --environment production
Screenshots
When you access your blog on port 8080 you should see your post. Some screenshots below:
Drone is a self-service continuous delivery platform which can be used for CICD pipelines, devopsy stuff which is really awesome.
With Configuration as Code, Pipelines are configured with a simple, easy‑to‑read file that you commit to your git repository such as github, gitlab, gogs, gitea etc.
Each Pipeline step is executed inside an isolated Docker container that is automatically downloaded at runtime, if not found in cache.
We will deploy a drone server which is responsible for the actual server and 2 drone agents which will receive instructions from the server whenever steps need to be executed. Steps run on agents.
Deploy the Servers
I’m using VULTR to deploy 3 nodes on coreos, 1 drone server and 2 drone agents as seen below:
Create the Startup Script for Drone Server, which will just be a docker container running in detached mode. Note that you should use your own domain at SERVER_HOST and if you want to issue an certificate automatically keep DRONE_TLS_AUTOCERT to true.
Logon to the server node and start the drone server:
1
$ bash start_drone-agent.sh
Login to the agent nodes and start the agents:
1
$ bash start_drone-agent.sh
The server should show that it’s listening on port 80 and 443:
123
$ docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES8ea70fc7b967 drone/drone:1 "/bin/drone-server" 12 minutes ago Up 12 minutes 0.0.0.0:80->80/tcp, 0.0.0.0:443->443/tcp drone
Access Drone
Access your Drone instance on port 80 eg. http://drone.yourdomain.com you should be automatically redirected to port 443, which should direct you to a login page, which will look like this:
Login with your github account and allow drone some time to sync your repositories:
We can also use custom webhook integrations to allow applications to notify us via slack in response of events.
What we will be doing
We will be configuring a custom slack webhook integration and test out the api to show you how easy it is to use it to inform us via slack, whenever something is happening.
Configuration
Head over to:
- https://{your-team}.slack.com/apps/manage/custom-integrations
curl -XPOST -d 'payload={"channel": "#system_events", "username": "My-WebhookBot", "text": "This is posted to #general and comes from a bot named <https://alert-system.com/alerts/1234|webhookbot> for details!", "icon_emoji": ":borat:"}' https://hooks.slack.com/services/xx/xx/xx
Will result in:
Message Attachment, Error:
1
curl -XPOST -d 'payload={"channel": "#system_events", "username": "My-WebhookBot", "text": "*Incoming Alert!*", "icon_emoji": ":borat:", "attachments":[{"fallback":"New open task [Urgent]: <http://url_to_task|Test out Slack message attachments>","pretext":"New open task [Urgent]: <http://url_to_task|Test out Slack message attachments>","color":"#D00000","fields":[{"title":"Notes","value":"This is much easier than I thought it would be.","short":false}]}]}}' https://hooks.slack.com/services/xx/xx/xx
Results in:
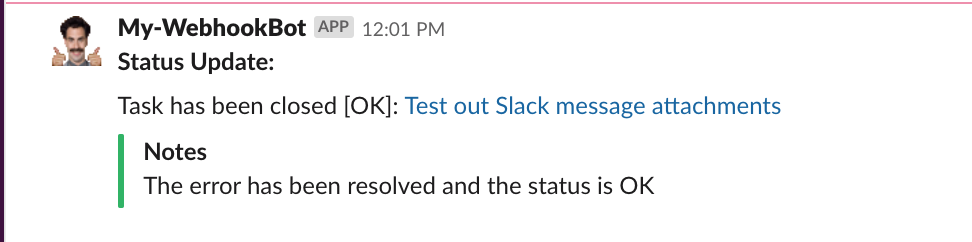
Message Attachment, OK:
1
curl -XPOST -d 'payload={"channel": "#system_events", "username": "My-WebhookBot", "text": "*Status Update:*", "icon_emoji": ":borat:", "attachments":[{"fallback":"New open task has been closed [OK]: <http://url_to_task|Test out Slack message attachments>","pretext":"Task has been closed [OK]: <http://url_to_task|Test out Slack message attachments>","color":"#28B463","fields":[{"title":"Notes","value":"The error has been resolved and the status is OK","short":false}]}]}}' https://hooks.slack.com/services/xx/xx/xx
While looking into working with mongodb using golang, I found it quite frustrating getting it up and running and decided to make a quick post about it.
What are we doing?
Examples using the golang driver for mongodb to connect, read, update and delete documents from mongodb.
packagemainimport("context""fmt""log""go.mongodb.org/mongo-driver/mongo""go.mongodb.org/mongo-driver/bson""go.mongodb.org/mongo-driver/mongo/options")typePersonstruct{NamestringAgeintCitystring}funcmain(){clientOptions:=options.Client().ApplyURI("mongodb://mongodb:27017")client,err:=mongo.Connect(context.TODO(),clientOptions)iferr!=nil{log.Fatal(err)}err=client.Ping(context.TODO(),nil)iferr!=nil{log.Fatal(err)}fmt.Println("Connected to MongoDB!")}
Running our app:
12
$ go run main.go
Connected to MongoDB!
Writing to MongoDB with Golang
Let’s insert a single document to MongoDB:
123456789101112
funcmain(){..collection:=client.Database("mydb").Collection("persons")ruan:=Person{"Ruan",34,"Cape Town"}insertResult,err:=collection.InsertOne(context.TODO(),ruan)iferr!=nil{log.Fatal(err)}fmt.Println("Inserted a Single Document: ",insertResult.InsertedID)}
Running it will produce:
123
$ go run main.go
Connected to MongoDB!
Inserted a single document: ObjectID("5cb717dcf597b4411252341f")
$ go run main.go
Matched 1 documents and updated 1 documents.
Reading Data from MongoDB
Reading the data:
12345678910111213141516
functmain(){..filter:=bson.DvarresultTrainererr=collection.FindOne(context.TODO(),filter).Decode(&result)iferr!=nil{log.Fatal(err)}fmt.Printf("Found a single document: %+v\n",result)findOptions:=options.Find()findOptions.SetLimit(2)}
12
$ go run main.go
Found a single document: {Name:Frankie Age:32 City:Nairobi}
Finding multiple documents and returning the cursor
12345678910111213141516171819202122232425
funcmain(){..varresults[]*Trainercur,err:=collection.Find(context.TODO(),bson.D,findOptions)iferr!=nil{log.Fatal(err)}forcur.Next(context.TODO()){varelemTrainererr:=cur.Decode(&elem)iferr!=nil{log.Fatal(err)}results=append(results,&elem)}iferr:=cur.Err();err!=nil{log.Fatal(err)}cur.Close(context.TODO())fmt.Printf("Found multiple documents (array of pointers): %+v\n",results)}
funcmain(){..deleteResult,err:=collection.DeleteMany(context.TODO(),bson.D)iferr!=nil{log.Fatal(err)}fmt.Printf("Deleted %v documents in the trainers collection\n",deleteResult.DeletedCount)err=client.Disconnect(context.TODO())iferr!=nil{log.Fatal(err)}else{fmt.Println("Connection to MongoDB closed.")}}
Running the example:
123
$ go run main.go
Deleted 3 documents in the trainers collection
Connection to MongoDB closed.
Let’s say you dont know the credit_card number but you would like to do a lookup the credit card number via the user’s id, then pass the value to the where statement:
Now, lets say the question will be that we need to display the users name, credit card number, product name as well as the product category and products price, by only giving you the credit card number