Concourse CI is a Continious Integration Platform. Concourse enables you to construct pipelines with a yaml configuration that can consist out of 3 core concepts, tasks, resources, and jobs that compose them. For more information about this have a look at their docs
What will we be doing today
We will setup a Concourse CI Server v6.7.6 (web and worker) on Ubuntu 20.04 and run the traditional Hello, World pipeline
Create SystemD Unit Files, first for the Web Service:
1234567891011121314
$ cat /etc/systemd/system/concourse-web.service
[Unit]Description=Concourse CI web process (ATC and TSA)After=postgresql.service
[Service]User=concourse
Restart=on-failure
EnvironmentFile=/etc/concourse/web_environment
ExecStart=/usr/bin/concourse web
[Install]WantedBy=multi-user.target
Then the SystemD Unit File for the Worker Service:
1234567891011121314
$ cat /etc/systemd/system/concourse-worker.service
[Unit]Description=Concourse CI worker process
After=concourse-web.service
[Service]User=root
Restart=on-failure
EnvironmentFile=/etc/concourse/worker_environment
ExecStart=/usr/bin/concourse worker
[Install]WantedBy=multi-user.target
Create a postgres password for the concourse user:
1234
$ cd /home/concourse/
$ sudo -u concourse psql atc
atc=> ALTER USER concourse WITH PASSWORD 'concourse';atc=> \q
Start and Enable the Services:
1234567
$ systemctl start concourse-web concourse-worker
$ systemctl enable concourse-web concourse-worker postgresql
$ systemctl status concourse-web concourse-worker
$ systemctl is-active concourse-worker concourse-web
active
active
The listening ports should more or less look like the following:
Next, we need to setup our Concourse Target by Authenticating against our Concourse Endpoint, lets setup our target with the name ci, and make sure to replace the ip address with the ip of your concourse server:
123456789
$ fly -t ci login -c http://10.20.30.40:8080
logging in to team 'main'navigate to the following URL in your browser:
http://10.20.30.40:8080/login?fly_port=42181
or enter token manually (input hidden):
target saved
Lets list our targets:
123
$ fly targets
name url team expiry
ci http://10.20.30.40:8080 main Wed, 08 Nov 2021 15:32:59 UTC
Listing Registered Workers:
123
$ fly -t ci workers
name containers platform tags team state version
10.20.30.40 0 linux none none running 1.2
Listing Active Containers:
12
$ fly -t ci containers
handle worker pipeline job build # build id type name attempt
Hello World Pipeline:
Let’s create a basic pipeline, that will print out Hello, World!:
$ fly -t ci set-pipeline -p yeeehaa -c hello-world.yml
jobs:
job my-job has been added:
name: my-job
plan:
- task: say-hello
config:
platform: linux
image_resource:
type: docker-image
source:
repository: alpine
tag: edge
run:
path: /bin/sh
args:
- -c
- |echo"============="echo"Hello, World!"echo"============="apply configuration? [yN]: y
pipeline created!
you can view your pipeline here: http://10.20.30.40:8080/teams/main/pipelines/yeeehaa
the pipeline is currently paused. to unpause, either:
- run the unpause-pipeline command - click play next to the pipeline in the web ui
We can browse to the WebUI to unpause the pipeline, but since I like to do everything on cli as far as possible, I will unpause the pipeline via cli:
12
$ fly -t ci unpause-pipeline -p yeeehaa
unpaused 'yeeehaa'
Now our Pipeline is unpaused, but since we did not specify any triggers, we need to manually trigger the pipeline to run, you can either via the WebUI, select your pipeline which in this case will be named yeeehaa and then select the job, which will be my-job then hit the + sign, which will trigger the pipeline.
I will be using the cli:
12
$ fly -t ci trigger-job --job yeeehaa/my-job
started yeeehaa/my-job #1
Via the WebUI on http://10.20.30.40:8080/teams/main/pipelines/yeeehaa/jobs/my-job/builds/1 you should see the Hello, World! output, or via the cli, we also have the option to see the output, so let’s trigger it again, but this time passing the --watch flag:
123456789101112
$ fly -t ci trigger-job --job yeeehaa/my-job --watch
started yeeehaa/my-job #2initializing
running /bin/sh -c echo"============="echo"Hello, World!"echo"============="=============Hello, World!
=============succeeded
Listing our Workers and Containers again:
1234567
$ fly -t ci workers
name containers platform tags team state version
10.20.30.40 2 linux none none running 1.2
$ fly -t ci containers
handle worker pipeline job build # build id type name attempt36982955-54fd-4c1b-57b8-216486c58db8 10.20.30.40 yeeehaa my-job 2729 task say-hello n/a
In this tutorial we will setup a Wireguard VPN with Unbound DNS Server with some additional configuration to block ads for any clients using the DNS Server while connected to the VPN.
A massive thank you to complexorganizations for providing the source where this tuturial is based off.
Install Packages
I will be using Debian Buster for this installation:
You can use SSM Session Manager to connect to your EC2 instances, as long as your EC2 instance has the associated IAM Role which includes the AmazonSSMManagedInstanceCore managed policy.
AWS EC2 Console
Head over to “Connect” and select “Session Manager”:
$ aws --profile prod ssm start-session --target i-0ebba722b102179b6
Starting session with SessionId: ruan.bekker-0b07cbbe261885ad3
sh-4.2$ sudo su - ec2-user
Last login: Wed Jan 6 12:55:03 UTC 2021 on pts/0
[ec2-user@ip-172-31-23-246 ~]$
Note: when you are using ssm session manager you don’t require security groups or a direct routable network to your instance.
$ ssh -i ~/.ssh/infra.pem ec2-user@i-0ebba722b102179b6
Warning: Permanently added 'i-0ebba722b102179b6' (ECDSA) to the list of known hosts.
Last login: Wed Jan 6 13:04:03 2021
__| __|_ )
_| ( / Amazon Linux 2 AMI
___|\___|___|
https://aws.amazon.com/amazon-linux-2/
[ec2-user@ip-172-31-23-246 ~]$
In this tutorial we will generate Loki Log links from selected dropdown template variables in a Grafana Dashboard.
Context
To give more context, we have a Grafana Dashboard with all our services, and when you select that service you see all the metrics of that service, now if you want to see the logs of that service, the selected label values will be parsed to a log link which you can click and it will take you to the Loki Explorer and parse the label values to the log link, so your logql will already be generated for you.
In order to achieve this, our metrics and logs need to share the same labels and label values (environment, container_name) etc.
Dashboard Variables
First we have our environment variable:
And here we have our service variable:
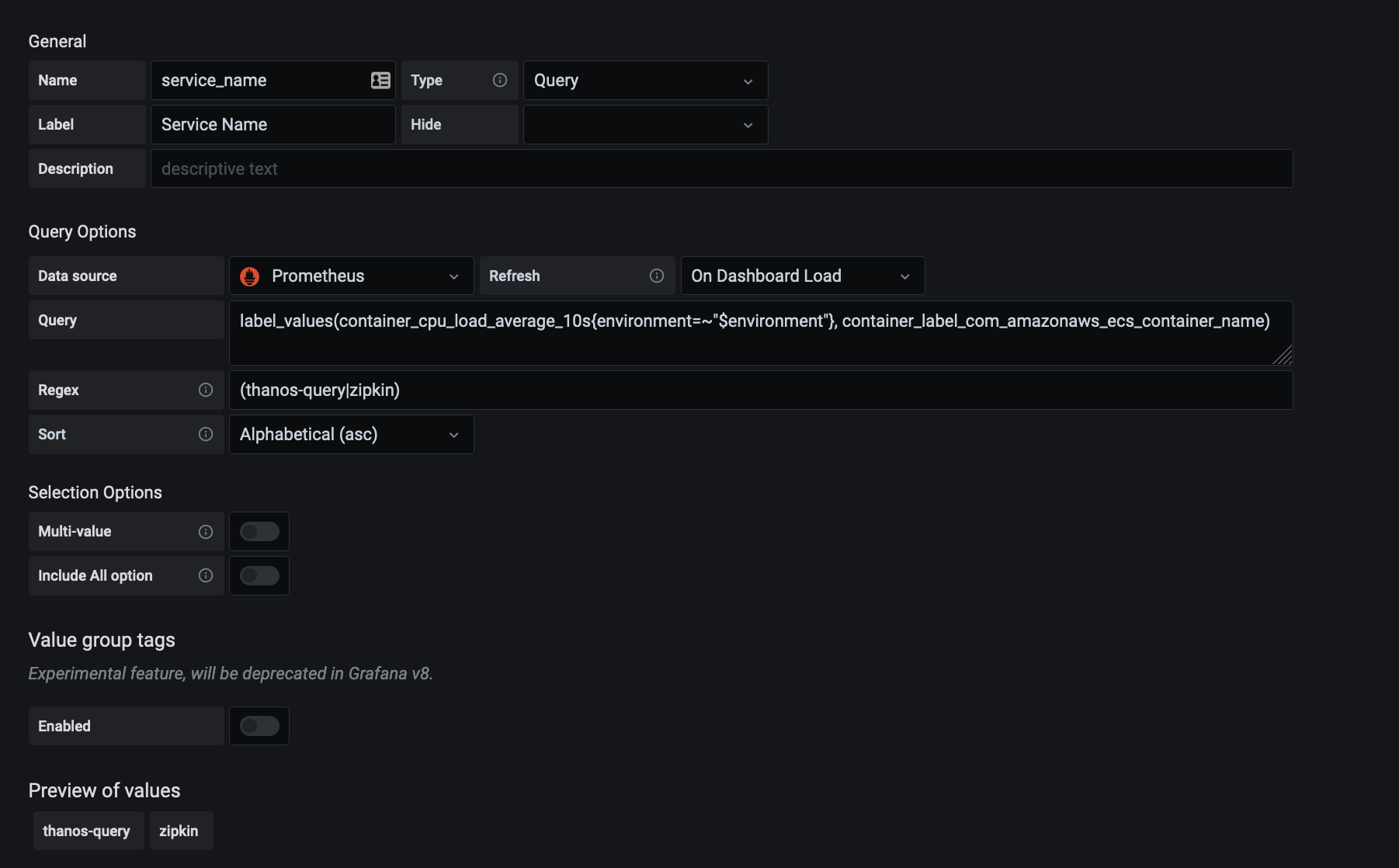
Then for our container_name we have:
Notice the /^(.*?)-[0-9]/ thats just to strip the end, if we remove it it will be:
Grafana Dashboard
Now when we select the environment, service, we get presented with a Loki LogURL:
If we look at our dashboard links, under the dashboard settings:
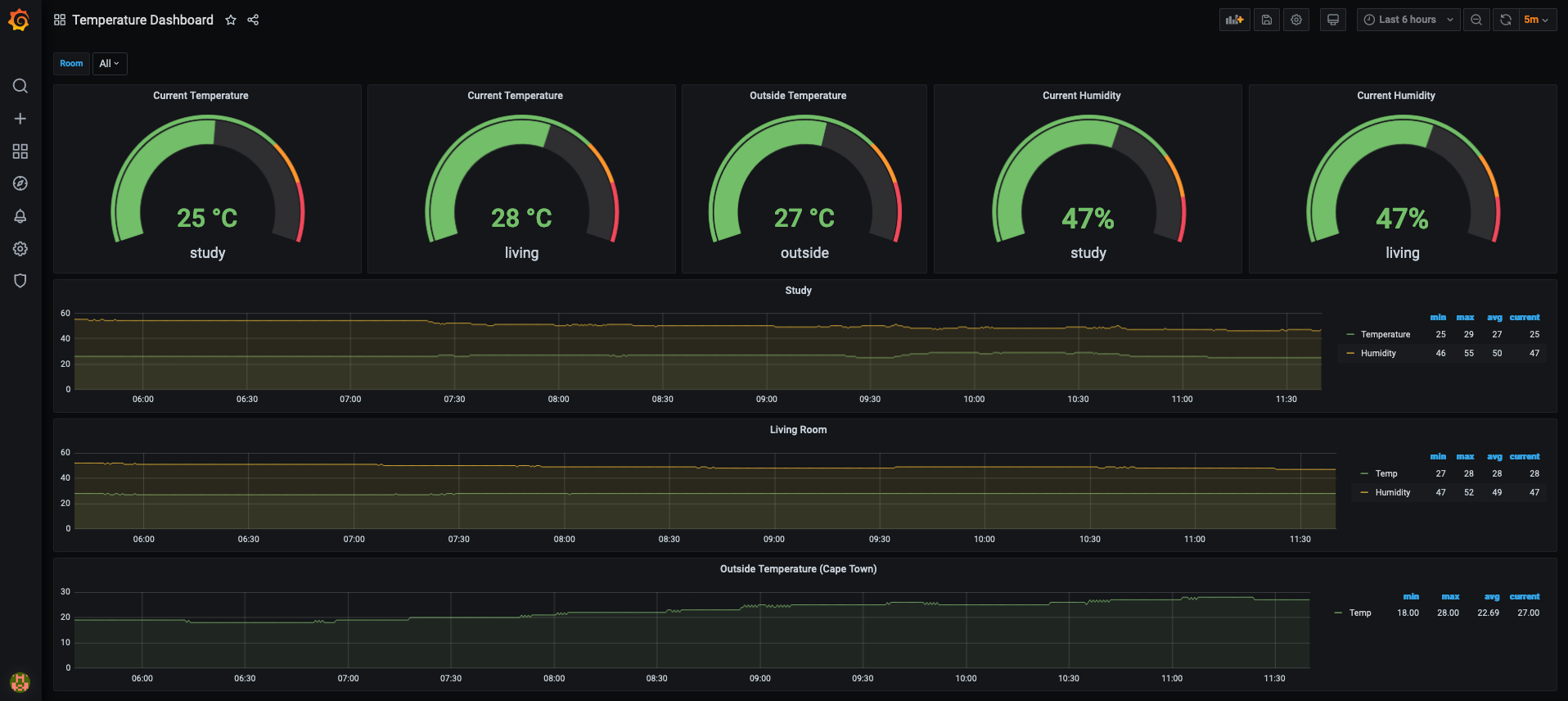
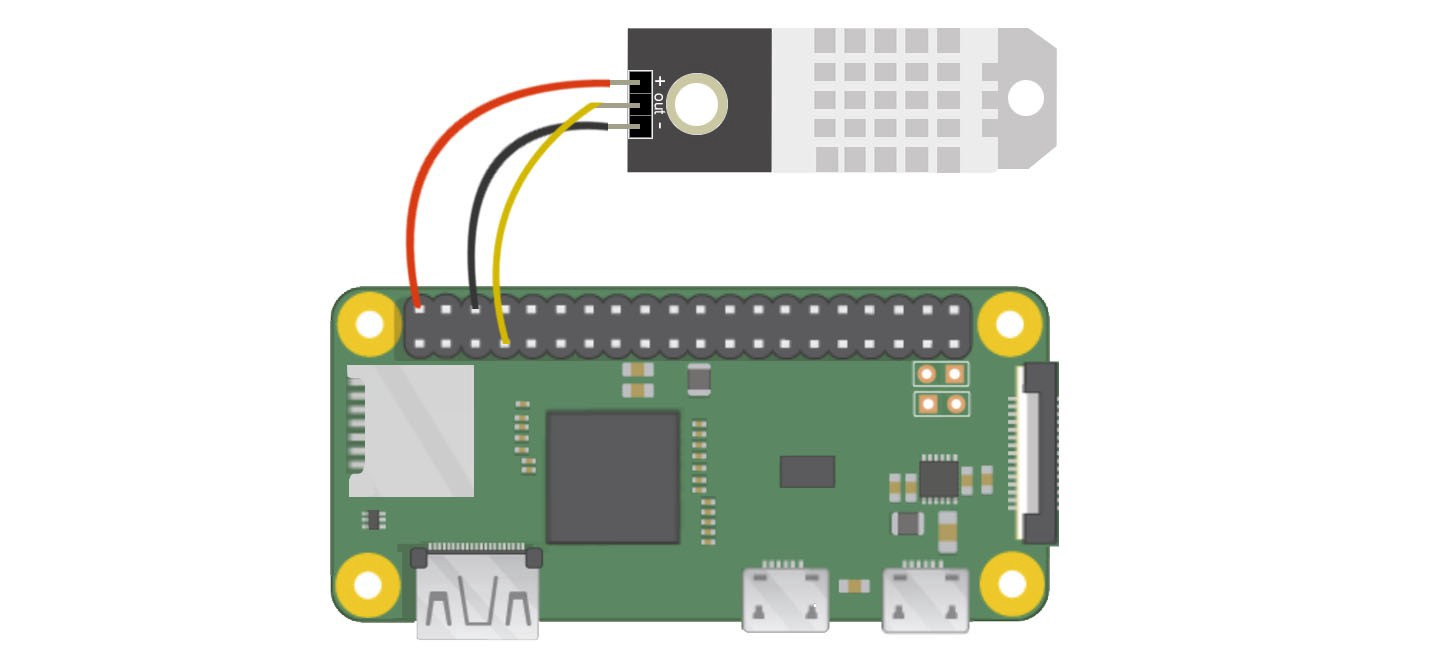
In this tutorial, we will connect the DHT22 sensor to the Raspberry Pi Zero via the GPIO pins to measure temperature and humidity and visualize it with Grafana.
$ cat flask_temps.py
#!/usr/bin/env python3
import Adafruit_DHT as dht_sensor
import time
from flask import Flask, Response
from prometheus_client import Counter, Gauge, start_http_server, generate_latest
import requests
params = {"lat": "-xx.xxxxx", "lon": "xx.xxxx", "units": "metric", "appid": "your-api-key"}
baseurl = "https://api.openweathermap.org/data/2.5/weather"
content_type = str('text/plain; version=0.0.4; charset=utf-8')
def get_temperature_readings():
humidity, temperature = dht_sensor.read_retry(dht_sensor.DHT22, 4)
humidity = format(humidity, ".2f")
temperature = format(temperature, ".2f")
outside_temp = get_outside_weather()
if all(v is not None for v in [humidity, temperature, outside_temp]):
response = {"temperature": temperature, "humidity": humidity, "outside_temp": outside_temp}
return response
else:
time.sleep(0.2)
humidity, temperature = dht_sensor.read_retry(dht_sensor.DHT22, 4)
humidity = format(humidity, ".2f")
temperature = format(temperature, ".2f")
outside_temp = get_outside_weather()
response = {"temperature": temperature, "humidity": humidity, "outside_temp": outside_temp}
return response
def get_outside_weather():
response = requests.get(baseurl, params=params)
temp = response.json()['main']['temp']
return temp
app = Flask(__name__)
current_humidity = Gauge(
'current_humidity',
'the current humidity percentage, this is a gauge as the value can increase or decrease',
['room']
)
current_temperature = Gauge(
'current_temperature',
'the current temperature in celsius, this is a gauge as the value can increase or decrease',
['room']
)
current_temperature_outside = Gauge(
'current_temperature_outside',
'the current outside temperature in celsius, this is a gauge as the value can increase or decrease',
['location']
)
@app.route('/metrics')
def metrics():
metrics = get_temperature_readings()
current_humidity.labels('study').set(metrics['humidity'])
current_temperature.labels('study').set(metrics['temperature'])
current_temperature_outside.labels('za_ct').set(metrics['outside_temp'])
return Response(generate_latest(), mimetype=content_type)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
Then install the flask and prometheus_client package:
$ curl http://localhost:5000/metrics
# HELP python_gc_objects_collected_total Objects collected during gc
# TYPE python_gc_objects_collected_total counter
python_gc_objects_collected_total{generation="0"} 646.0
python_gc_objects_collected_total{generation="1"} 129.0
python_gc_objects_collected_total{generation="2"} 0.0
# HELP python_gc_objects_uncollectable_total Uncollectable object found during GC
# TYPE python_gc_objects_uncollectable_total counter
python_gc_objects_uncollectable_total{generation="0"} 0.0
python_gc_objects_uncollectable_total{generation="1"} 0.0
python_gc_objects_uncollectable_total{generation="2"} 0.0
# HELP python_gc_collections_total Number of times this generation was collected
# TYPE python_gc_collections_total counter
python_gc_collections_total{generation="0"} 104.0
python_gc_collections_total{generation="1"} 9.0
python_gc_collections_total{generation="2"} 0.0
# HELP python_info Python platform information
# TYPE python_info gauge
python_info{implementation="CPython",major="3",minor="7",patchlevel="3",version="3.7.3"} 1.0
# HELP process_virtual_memory_bytes Virtual memory size in bytes.
# TYPE process_virtual_memory_bytes gauge
process_virtual_memory_bytes 4.4761088e+07
# HELP process_resident_memory_bytes Resident memory size in bytes.
# TYPE process_resident_memory_bytes gauge
process_resident_memory_bytes 2.7267072e+07
# HELP process_start_time_seconds Start time of the process since unix epoch in seconds.
# TYPE process_start_time_seconds gauge
process_start_time_seconds 1.61044381853e+09
# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.
# TYPE process_cpu_seconds_total counter
process_cpu_seconds_total 5.86
# HELP process_open_fds Number of open file descriptors.
# TYPE process_open_fds gauge
process_open_fds 6.0
# HELP process_max_fds Maximum number of open file descriptors.
# TYPE process_max_fds gauge
process_max_fds 1024.0
# HELP current_humidity the current humidity percentage, this is a gauge as the value can increase or decrease
# TYPE current_humidity gauge
current_humidity{room="study"} 47.0
# HELP current_temperature the current temperature in celsius, this is a gauge as the value can increase or decrease
# TYPE current_temperature gauge
current_temperature{room="study"} 25.7
# HELP current_temperature_outside the current outside temperature in celsius, this is a gauge as the value can increase or decrease
# TYPE current_temperature_outside gauge
current_temperature_outside{location="za_ct"} 27.97
Now to configure our prometheus scrape config to scrape our endpoint:
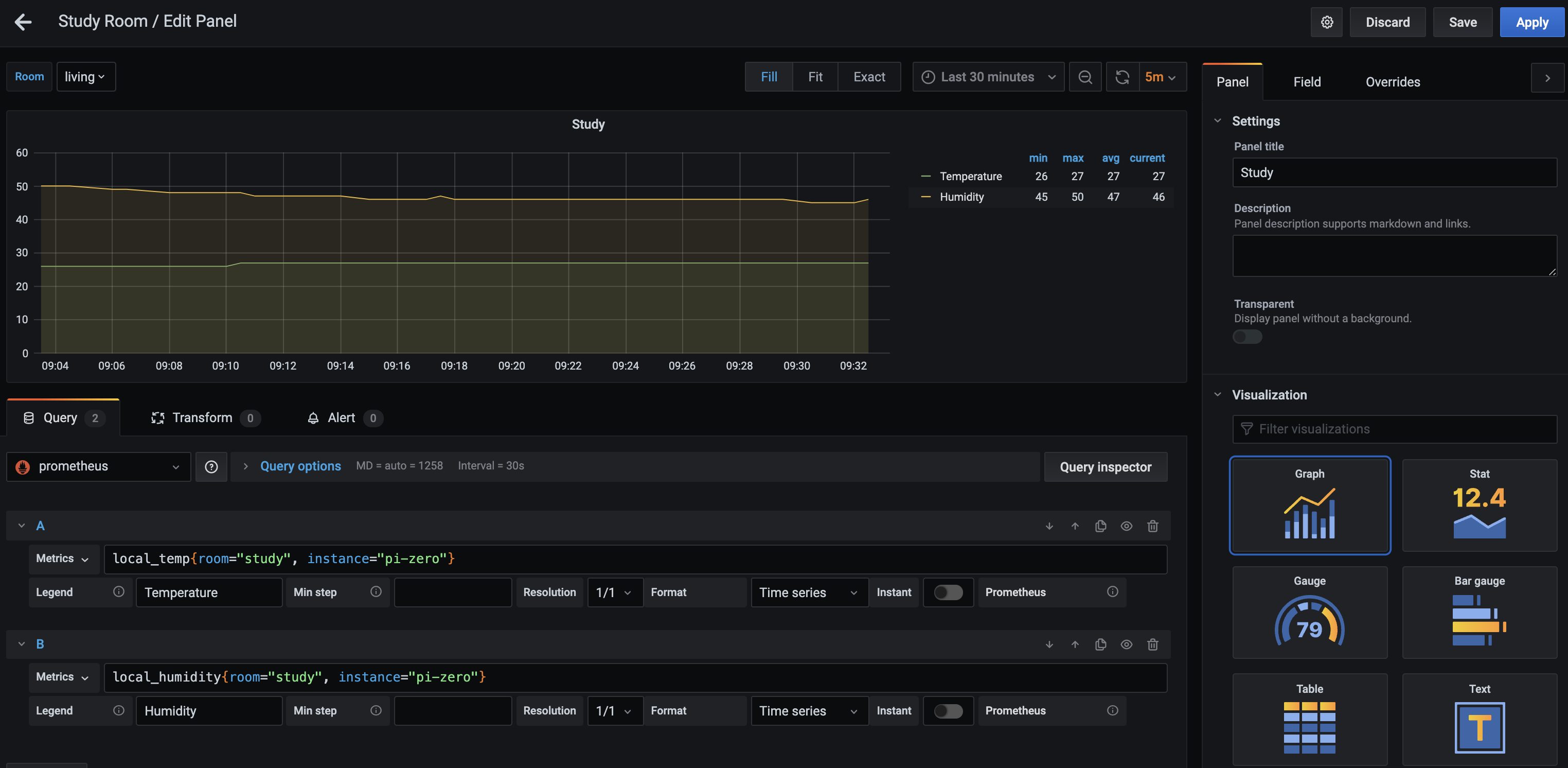
We will be adding a new panel with a graph visualization, and from our prometheus datasource, we will be referencing the 2 metrics (different from the screenshot):
In this post we wil set up a drone-ci and gitea stack using docker-compose and then running a test pipeline.
I have posted a few times about this topic, but this post will be used when I create other examples and wanting to use this post for the ones not having the stack booted yet.
IP_ADDRESS=192.168.0.6 -> either reachable dns or ip address which will be your clone address and ui addresses.
GITEA_ADMIN_USER="giteauser" -> will be the user you register with in drone
Now boot the stack:
1
$ bash boot.sh
Note: Theres a current issue where webhooks get fired twice, if you see that just restart gitea with docker restart gitea.
Head over to: http://${IP_ADDRESS}:3000/user/settings/applications and create a new OAuth2 Application and set the Redirect URI to http://${IP_ADDRESS}:3001/login
Capture the client id and client secret and populate them in the boot.sh in DRONE_GITEA_CLIENT_ID and DRONE_GITEA_CLIENT_SECRET and run bash boot.sh again. This will give drone the correct credentials in order to authenticate with gitea.
Now when you head over to http://${IP_ADDRESS}:3001/ you will be asked to authorize the application and you should be able to access drone.
The fluent-bit container listens on port 24224 locally on our docker host and is not reachable via its container network, so let’s boot our application:
1
$ docker-compose -f docker-compose-app.yml up -d
Once our application is up, let’s make a request to our nginx-app:
12
$ curl http://localhost:8080/
ok
Now head over to Grafana at http://localhost:3000/explore and query: {job="fluent-bit", container_name="/nginx-app"} and you should see something like this:
Once installed you can reference arduino-esp32 for your operating system, but in general you will open the Arduino application, select Preferences and provide the following link on the “Additional Boards Manager URL”:
Hit OK, then select Tools, Board, Board Manager, then search for “esp32”, then install esp32 by Espressif Systems:
Then make sure to select the board by navigating to Tools, Board, ESP32 Arduino, ESP32 Dev Module:
Select the upload rate from Tools, Upload Rate to 115200 and select the serial port, from mine it is Tools, Port, usb-serial-0001 (your’s might differ)
Hello World Application
Now that we have Arduino installed and our board configured, let’s write a hello world application, from the input text section:
From the setup function we set the baud rate and print a line then sleep for 5 seconds, once that is done we call the loop function which will print “Hello, World” and sleep for 1 second, and that will loop indefinitely.
Once you are done, save your sketch and upload it to the board by either selecting the upload button or from Sketch, Upload.
When the code has been compiled the device will reset and you can open the serial monitor, by selecting Tools, Serial Monitor:
In cases where you are using the defaults for logging and your application logs a lot you can consume a lot of disk space and you can run out of disk space quite quickly.
If it’s a case where you already ran out of disk space, we can investigate the disk space consumed by docker logs:
1234
$ cd /var/lib/docker/containers
$ du -sh *
6.0G 14052251a0f13f46f65bc73d10c01408130ee8ae71529600ba5bd6bee76af4ee
1.2G e6b40b1d30c5cf05e8cb201ca9abf6bd283d7cf7ceaa3be2a0422be7cd750a33