Please feel free to show support by, sharing this post, making a donation, subscribing or reach out to me if you want me to demo and write up on any specific tech topic.
a Quick post on how to change your relayhost on Postfix to a External SMTP Provider and aswell how to revert back the changes so the Relay server sends out mail directly.
Checking your current relayhost configuration:
We will assume your /etc/postfix/main.cf has a relayhost entry of #relayhost =, in my example it will look like this:
12
$ cat /etc/postfix/main.cf
#relayhost =
If not, you can just adjust your sed command accordingly.
Changing your relayhost configuration to a External SMTP Provider:
We will use sed to change the relayhost to za-smtp-outbound-1.mimecast.co.za for example:
1
$ sed -i 's/#relayhost\ =/relayhost\ =\ \[za-smtp-outbound-1.mimecast.co.za\]/g' /etc/postfix/main.cf
to verify that we have set the config, look at the config:
As you can see the relayhost is commented out, meaning that the relayhost property will not be active, go ahead and restart the service for the changes to take effect:
1
$ /etc/init.d/postfix restart
Same as before, look at the logs to confirm mailflow is as expected:
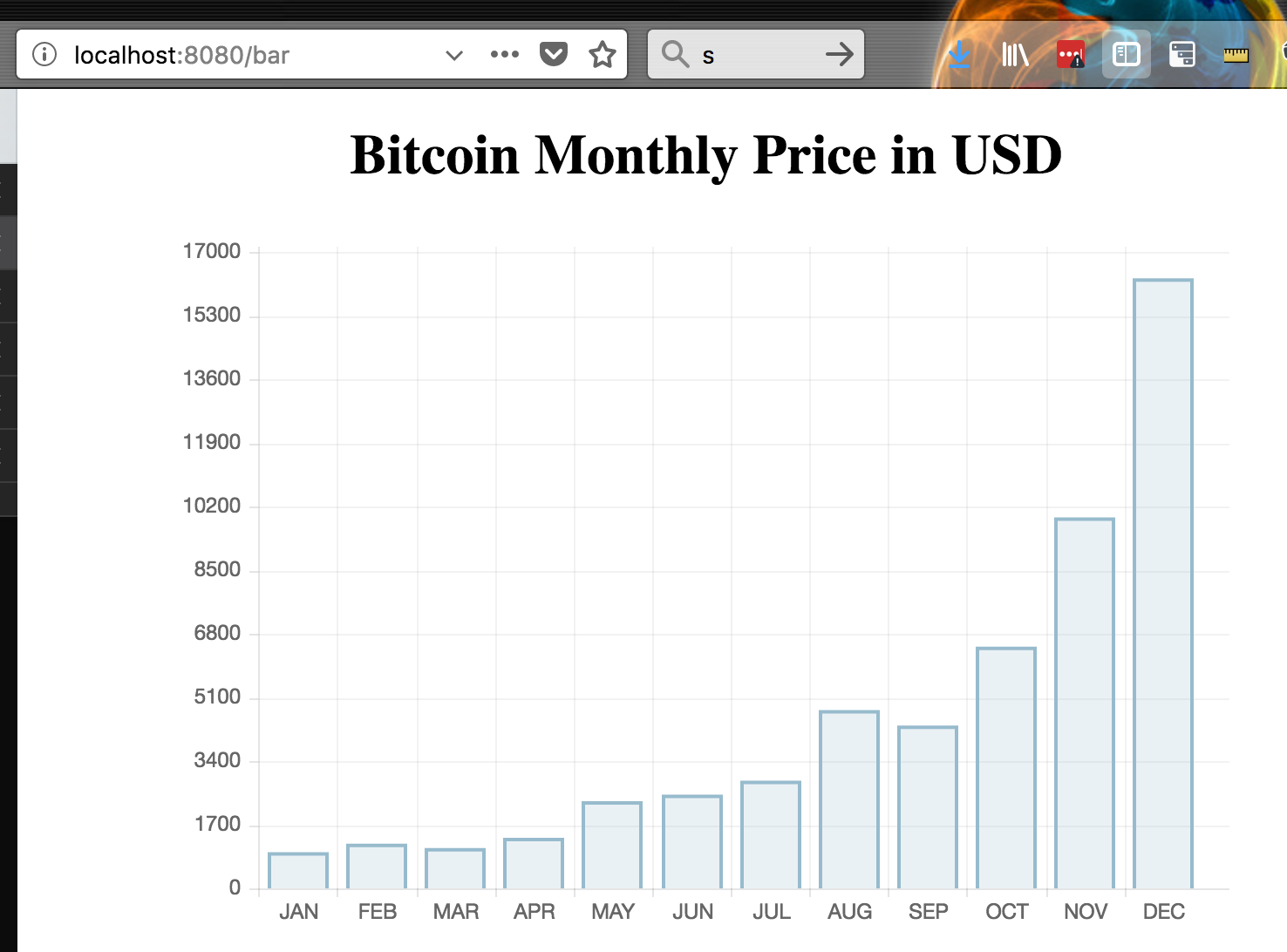
I am a big sucker for Charts and Graphs, and today I found one awesome library called Chart.js, which we will use with Python Flask Web Framework, to graph our data.
As Bitcoin is doing so well, I decided to graph the monthly Bitcoin price from January up until now.
Dependencies:
Install Flask:
1
$ pip install flask
Create the files and directories:
12
$ touch app.py
$ mkdir templates
We need the Chart.js library, but I will use the CDN version, in my html.
Creating the Flask App:
Our data that we want to graph will be hard-coded in our application, but there are many ways to make this more dynamic, in your app.py:
fromflaskimportFlask,Markup,render_templateapp=Flask(__name__)labels=['JAN','FEB','MAR','APR','MAY','JUN','JUL','AUG','SEP','OCT','NOV','DEC']values=[967.67,1190.89,1079.75,1349.19,2328.91,2504.28,2873.83,4764.87,4349.29,6458.30,9907,16297]colors=["#F7464A","#46BFBD","#FDB45C","#FEDCBA","#ABCDEF","#DDDDDD","#ABCABC","#4169E1","#C71585","#FF4500","#FEDCBA","#46BFBD"]@app.route('/bar')defbar():bar_labels=labelsbar_values=valuesreturnrender_template('bar_chart.html',title='Bitcoin Monthly Price in USD',max=17000,labels=bar_labels,values=bar_values)@app.route('/line')defline():line_labels=labelsline_values=valuesreturnrender_template('line_chart.html',title='Bitcoin Monthly Price in USD',max=17000,labels=line_labels,values=line_values)@app.route('/pie')defpie():pie_labels=labelspie_values=valuesreturnrender_template('pie_chart.html',title='Bitcoin Monthly Price in USD',max=17000,set=zip(values,labels,colors))if__name__=='__main__':app.run(host='0.0.0.0',port=8080)
Populating the HTML Static Content:
As we are using render_template we need to populate our html files in our templates/ directory. As you can see we have 3 different html files:
templates/bar_chart.html :
templates/line_chart.html:
templates/pie_chart.html:
Running our Application:
As you can see, we have 3 endpoints, each representing a different chart style:
So I’ve been wanting to take a stab at chatbots for some time, and recently discovered Chatterbot, so in this tutorial I will go through some examples on setting up a very basic chatbot.
Getting the Dependencies:
I will be using Alpine on Docker to run all the the examples, I am using Alpine so that we have a basic container with nothing special pre-installed.
Chatterbot is written in Python, so let’s install Python and Chatterbot:
Now that our dependencies is installed, enter the Python interpreter where we will instantiate our Chatbot, and get a response from our Chatbot. By default the library will create a sqlite database to build up statements that is passed to and from the bot.
At this point, the bot is still pretty useless:
1234567
$ python
>>> from chatterbot import ChatBot
>>> chatbot= ChatBot('Ben')>>> chatbot.get_response('What is your name?')<Statement text:What is your name?>
>>> chatbot.get_response('My name is Ruan, what is your name?')<Statement text:What is your name?>
Training your Bot:
To enable your bot to have some knowledge, we can train the bot with training data. The training data is populated in a list, which will represent the conversation.
Exit the python interpreter and delete the sqlite database:
1
$ rm -rf db.sqlite3
Now our Bot wont have any history of what we said. Start the interpreter again and add some data to train our bot. In this example, we want our Chatbot to respond when we ask it, what his name is:
123456
>>> from chatterbot import ChatBot
>>> from chatterbot.trainers import ListTrainer
>>> chatbot= ChatBot('Ben')>>> chatbot.set_trainer(ListTrainer)>>> chatbot.train(['What is your name?', 'My name is Ben'])List Trainer: [####################] 100%
Now that we have trained our bot, let’s try to chat to our bot:
1234
>>> chatbot.get_response('What is your name?')<Statement text:My name is Ben>
>>> chatbot.get_response('Who is Ben?')<Statement text:My name is Ben>
We can also enable our bot to respond on multiple statements:
1234567
>>> chatbot.train(['Do you know someone with the name of Sarah?', 'Yes, my sisters name is Sarah', 'Is your sisters name, Sarah?', 'Faw shizzle!'])List Trainer: [####################] 100%>>> chatbot.get_response('do you know someone with the name of Sarah?')<Statement text:Yes, my sisters name is Sarah>
>>> chatbot.get_response('is your sisters name Sarah?')<Statement text:Faw shizzle!>
With that said, we can define our list of statements in our code:
1234567891011
>>>conversations=[...'Are you an athlete?','No, are you mad? I am a bot',...'Do you like big bang theory?','Bazinga!',...'What is my name?','Ruan',...'What color is the sky?','Blue, stop asking me stupid questions'...]>>>chatbot.train(conversations)ListTrainer:[####################] 100%>>>chatbot.get_response('What color is the sky?')<Statementtext:Blue,stopaskingmestupidquestions>
So we can see it works as expected, but let’s state one of the answers from our statements, to see what happens:
1234
>>> chatbot.get_response('Bazinga')<Statement text:What is my name?>
>>> chatbot.get_response('Your name is Ben')<Statement text:Yes, my name is Ben>
So we can see it uses natural language processing to learn from the data that we provide our bot. Just to check another question:
12
>>> chatbot.get_response('Do you like big bang theory?')<Statement text:Bazinga!>
If we have quite a large subset of learning data, we can add all the data in a file, seperated by new lines then we can use python to read the data from disk, and split up the data in the expected format.
The training file will reside in our working directory, let’s name it training-data.txt and the content will look like this:
1234
What is Bitcoin?
Bitcoin is a Crypto Currency
Where is this blog hosted?
Github
A visual example of how we will process this data will look like this:
123
>>> data= open('training-data.txt').read()>>> data.strip().split('\n')['What is Bitcoin?', 'Bitcoin is a Crypto Currency', 'Where is this blog hosted?', 'Github']
And in action, it will look like this:
1234567
>>> data= open('training-data.txt').read()>>> conversations= data.strip().split('\n')>>> chatbot.train(conversations)List Trainer: [####################] 100%>>> chatbot.get_response('Where is this blog hosted?')<Statement text:Github>
There is also pre-populated data that you can use to train your bot, on the documentation is a couple of examples, but for demonstration, we will use the CorpusTrainer:
>>> from chatterbot.trainers import ChatterBotCorpusTrainer
>>> chatterbot.set_trainer(ChatterBotCorpusTrainer)>>> chatbot.train("chatterbot.corpus.english")ai.yml Training: [####################] 100%botprofile.yml Training: [####################] 100%computers.yml Training: [####################] 100%conversations.yml Training: [####################] 100%emotion.yml Training: [####################] 100%food.yml Training: [####################] 100%gossip.yml Training: [####################] 100%greetings.yml Training: [####################] 100%history.yml Training: [####################] 100%humor.yml Training: [####################] 100%literature.yml Training: [####################] 100%money.yml Training: [####################] 100%movies.yml Training: [####################] 100%politics.yml Training: [####################] 100%psychology.yml Training: [####################] 100%science.yml Training: [####################] 100%sports.yml Training: [####################] 100%trivia.yml Training: [####################] 100%>>> chatbot.get_response('Do you like peace?')<Statement text:not especially. i am not into violence.>
>>> chatbot.get_response('Are you emotional?')<Statement text:Sort of.>
>>> chatbot.get_response('What language do you speak?')<Statement text:Python.>
>>> chatbot.get_response('What is your name?')<Statement text:My name is Ben>
>>> chatbot.get_response('Who is the President of America?')<Statement text:Richard Nixon> #data seems outdated :D>>> chatbot.get_response('I like cheese')<Statement text:What kind of movies do you like?>
Using an External Database like MongoDB
Instead of using sqlite on the same host, we can use a NoSQL Database like MongoDB that resides outside our application.
For the sake of this tutorial, I will use Docker to spin up a MongoDB Container:
Below is my code of a terminal application that uses Chatterbot, MongoDB as a Storage Adapter, and we are using a while loop, so that we can chat with our bot, and in our except statement, we can stop our application by using our keyboard to exit:
fromchatterbotimportChatBotfromchatterbot.trainersimportChatterBotCorpusTrainerchatbot=ChatBot("Chatbot Backed by MongoDB",storage_adapter="chatterbot.storage.MongoDatabaseAdapter",database="chatterbot_db",database_uri="mongodb://172.17.0.3:27017/",logic_adapters=['chatterbot.logic.BestMatch'],trainer='chatterbot.trainers.ChatterBotCorpusTrainer',filters=['chatterbot.filters.RepetitiveResponseFilter'],input_adapter='chatterbot.input.TerminalAdapter',output_adapter='chatterbot.output.TerminalAdapter')chatbot.set_trainer(ChatterBotCorpusTrainer)chatbot.train("chatterbot.corpus.english")print('Chatbot Started:')whileTrue:try:print(" -> You:")botInput=chatbot.get_response(None)except(KeyboardInterrupt,EOFError,SystemExit):break
Running the example:
1234567
$ python bot.py
-> You:
How are you?
I am doing well.
-> You:
Tell me a joke
A 3-legged dog walks into an old west saloon, slides up to the bar and announces "I'm looking for the man who shot my paw."
And from mongodb, we can see some data:
1234567891011121314151617181920
$ mongo
> show dbs
admin 0.078GB
chatterbot_db 0.078GB
local 0.078GB
> use chatterbot_db
switched to db chatterbot_db
> show collections;conversations
statements
system.indexes
> db.conversations.find().count()4
> db.statements.find().count()1240
> db.system.indexes.find().count()3
That was a basic tutorial on Chatterbot, next I will be looking into mining data from Twitter’s API and see how clever our bot can become.
When you format / reload a server and the host gets the same IP, when you try to SSH to that host, you might get a warning like this:
1234567891011121314
$ ssh 192.168.1.104
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY!
Someone could be eavesdropping on you right now (man-in-the-middle attack)!
It is also possible that a host key has just been changed.
The fingerprint for the ECDSA key sent by the remote host is
a1:a2:a3:a4:a5:a6:a7:a8:a9:b0:b1:b2:b3:b4:b5:b6.
Please contact your system administrator.
Add correct host key in /home/pi/.ssh/known_hosts to get rid of this message.
Offending ECDSA key in /home/pi/.ssh/known_hosts:10
ECDSA host key for 192.168.1.104 has changed and you have requested strict checking.
Host key verification failed.
This is because we have StrictMode enabled in our SSH Configuration:
To remove the offending key from your known_hosts file, without opening it, you can use ssh-keygen to remove it:
1234
$ ssh-keygen -f .ssh/known_hosts -R 192.168.1.104
# Host 192.168.1.104 found: line 10 type ECDSA.ssh/known_hosts updated.
Original contents retained as .ssh/known_hosts.old
“Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications.”
Our Setup:
For this setup I will be using 3 AWS EC2 Instances with Ubuntu 16.04. One node will act as the master node, and the other 2 nodes, will act as nodes, previously named minions.
We will deploy Kubernetes on all 3 nodes, the master will be the node where we will initialize our cluster, deploy our weave network, applications and we will execute the join command on the worker nodes to join the master to form the cluster.
Deploy Kubernetes: Master
The following commands will be used to install Kubernetes, it will be executed with root permissions:
The output will provide you with instructions to setup the configurations for the master node, and provide you with a join token for your worker nodes, remember to make not of this token string, as we will need it later for our worker nodes. As your normal user, run the following to setup the config:
Remember to not run this as root, and as the normal user:
Lets confirm if all our resources are in its desired state, a small snippet of the output will look like the one below:
123456
$ kubectl get all -n kube-system
...
NAME READY STATUS RESTARTS AGE
po/etcd-ip-172-31-40-211 1/1 Running 0 6h
po/kube-apiserver-ip-172-31-40-211 1/1 Running 0 6h
Once all of the resources are in its desired state, we can head along to our worker nodes, to join them to the cluster
Deploy Kubernetes: Worker Nodes
As I have 2 worker nodes, we will need to deploy the following on both of our worker nodes, first to deploy Kubernetes on our nodes with root permission:
Do the 2 steps on the other node, then head back to the master node.
Verifying if All Nodes are Checked In
To verify if all nodes are available and reachable in the cluster:
12345
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-172-31-36-68 Ready <none> 6h v1.8.5
ip-172-31-40-211 Ready master 6h v1.8.5
ip-172-31-44-80 Ready <none> 6h v1.8.5
Give it about a minute or so, then you should see the pods running in their desired state:
1234567
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
alertmanager-77b4b476b-zxtcz 1/1 Running 0 4h
crypto-7d8b7f999c-7l85k 1/1 Running 0 1h
faas-netesd-64fb9b4dfb-hc8gh 1/1 Running 0 4h
gateway-69c9d949f-q57zh 1/1 Running 0 4h
prometheus-7fbfd8bfb8-d4cft 1/1 Running 0 4h
When we have the desired state, head over to the OpenFaas Gateway WebUI: http://master-public-ip:31112/ui/, select “Deploy New Function”, you can use your own function or select one from the store.
I am going to use Figlet from the store, once the pod has been deployed, select the function, enter any text into the request body and select invoke. I have used my name and surname, and turns out into:
I have a 3 Node MySQL Galera Cluster that faced a shutdown on all 3 nodes at the same time, luckily this is only a testing environment, but at that time it was down and did not want to start up.
Issues Faced
When trying to start MySQL the only error visible was:
12345
$ /etc/init.d/mysql restart
* MySQL server PID file could not be found!
Starting MySQL
........ * The server quit without updating PID file (/var/run/mysqld/mysqld.pid).
* Failed to restart server.
At that time I can see that the galera port is started, but not mysql:
12345678
$ ps aux | grep mysql
root 23580 0.0 0.0 45081800 pts/0 S 00:37 0:00 /bin/sh /usr/bin/mysqld_safe --datadir=/var/lib/mysql --pid-file=/var/run/mysqld/mysqld.pid
mysql 24144 0.7 22.2 1185116455660 pts/0 Sl 00:38 0:00 /usr/sbin/mysqld --basedir=/usr --datadir=/var/lib/mysql --plugin-dir=/usr/lib/mysql/plugin --user=mysql --log-error=/var/log/mysql/error.log --pid-file=/var/run/mysqld/mysqld.pid --socket=/var/run/mysqld/mysqld.sock --port=3306 --wsrep_start_position=long:string
$ netstat -tulpn
Active Internet connections (only servers)Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 00 0.0.0.0:4567 0.0.0.0:* LISTEN 25507/mysqld
Why?
More in detail is explained on a SeveralNines Blog Post, but due to the fact that all the nodes left the cluster, one of the nodes needs to be started as a referencing point, before the other nodes can rejoin or bootstrapped to the cluster.
Rejoining the Cluster
Consult the blog for more information, but from my end, I had a look at the node with the highest seqno and then updated safe_to_bootstrap to 1:
I was busy setting up a docker-volume-netshare plugin to use NFS Volumes for Docker, which relies on the nfs-utils/nfs-common package, and when trying to start the service, I found that the nfs-common service is masked:
12
$ sudo systemctl start docker-volume-netshare.service
Failed to start docker-volume-netshare.service: Unit nfs-common.service is masked.
Looking at the nfs-common service:
1234567
$ sudo systemctl is-enabled nfs-common
masked
$ sudo systemctl enable nfs-common
Synchronizing state of nfs-common.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable nfs-common
Failed to enable unit: Unit file /lib/systemd/system/nfs-common.service is masked.
It appears that the unit file has a symbolic link to /dev/null:
12
$ file /lib/systemd/system/nfs-common.service
/lib/systemd/system/nfs-common.service: symbolic link to /dev/null
I was able to unmask the service by removing the file:
1
$ sudo rm /lib/systemd/system/nfs-common.service
Then reloading the daemon:
1
$ sudo systemctl daemon-reload
As we can see the nfs-common service is not running:
12345
$ sudo systemctl status nfs-common
● nfs-common.service - LSB: NFS support files common to client and server
Loaded: loaded (/etc/init.d/nfs-common; generated; vendor preset: enabled) Active: inactive (dead) Docs: man:systemd-sysv-generator(8)
Let’s go ahead and start the service:
12345678910
$ sudo systemctl start nfs-common
$ sudo systemctl status nfs-common
● nfs-common.service - LSB: NFS support files common to client and server
Loaded: loaded (/etc/init.d/nfs-common; generated; vendor preset: enabled) Active: active (running) since Sat 2017-12-09 08:59:47 SAST; 2s ago
Docs: man:systemd-sysv-generator(8) Process: 7382ExecStart=/etc/init.d/nfs-common start (code=exited, status=0/SUCCESS) CPU: 162ms
CGroup: /system.slice/nfs-common.service
└─7403 /usr/sbin/rpc.idmapd
Now we can see the serive is unmasked and started, also remember to enable to service on boot:
123456
$ sudo systemctl enable nfs-common
nfs-common.service is not a native service, redirecting to systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable nfs-common
$ sudo systemctl is-enabled nfs-common
enabled
Thanks for reading, feel free to check out my website, feel free to subscribe to my newsletter or follow me at @ruanbekker on Twitter.