In this post we will demonstrate how to use a SSH Bastion or Jump Host with Ansible to reach the target server.
In some scenarios, the target server might be in a private range which is only accessible via a bastion host, and that counts the same for ansible as ansible is using SSH to reach to the target servers.
SSH Config
Our bastion host is configured as bastion and the config under ~/.ssh/config looks like this:
1234567891011
Host *
Port 22
StrictHostKeyChecking no
UserKnownHostsFile /dev/null
ServerAliveInterval 60
ServerAliveCountMax 30
Host bastion
HostName bastion.mydomain.com
User bastion
IdentityFile ~/.ssh/id_rsa
To verify that our config is working, you should be able to use:
1
$ ssh bastion
Using a Bastion with Ansible
In order to reach our target server we need to use the bastion, so to test the SSH connection we can use this SSH one-liner. Our target server has a IP address of 172.31.81.94 and expects us to provide a ansible.pem private key and we need to authenticate with the ubuntu user:
Our inventory.ini includes the hosts that we will be using, and in this case I will be defining a group named rpifleet with all the host nested under that group and I’m using the user pi and my private ssh key ~/.ssh/id_rsa:
In this post we will use the libvirt provisioner with Terraform to deploy a KVM Virtual Machine on a Remote KVM Host using SSH and use Ansible to deploy Nginx on our VM.
In my previous post I demonstrated how I provisioned my KVM Host and created a dedicated user for Terraform to authenticate to our KVM host to provision VMs.
Once you have KVM installed and your SSH access is sorted, we can start by installing our dependencies.
Create the main.tf, you will notice that we are using ssh to connect to KVM, and because the private range of our VM’s are not routable via the internet, I’m using a bastion host to reach them.
The bastion host (ssh config from the pre-requirements section) is the KVM host and you will see that ansible is also using that host as a jump box, to get to the VM. I am also using cloud-init to bootstrap the node with SSH, etc.
The reason why I’m using remote-exec before the ansible deployment, is to ensure that we can establish a command via SSH before Ansible starts.
And lastly, our outputs.tf which will display our IP address of our VM:
1234567
output "ip" {
value = libvirt_domain.domain-ubuntu.network_interface[0].addresses[0]
}
output "url" {
value = "http://${libvirt_domain.domain-ubuntu.network_interface[0].addresses[0]}"
}
Deploy our Terraform Deployment
It’s time to deploy a KVM instance with Terraform and deploy Nginx to our VM with Ansible using the local-exec provisioner.
Initialize terraform to download all the plugins:
12345678910111213141516171819202122
$ terraform init
Initializing the backend...
Initializing provider plugins...
- Finding latest version of hashicorp/template...
- Finding dmacvicar/libvirt versions matching "0.6.2"...
- Installing hashicorp/template v2.1.2...
- Installed hashicorp/template v2.1.2 (signed by HashiCorp)
- Installing dmacvicar/libvirt v0.6.2...
- Installed dmacvicar/libvirt v0.6.2 (unauthenticated)
The following providers do not have any version constraints in configuration,
so the latest version was installed.
To prevent automatic upgrades to new major versions that may contain breaking
changes, we recommend adding version constraints in a required_providers block
in your configuration, with the constraint strings suggested below.
* hashicorp/template: version = "~> 2.1.2"
Terraform has been successfully initialized!
Run a plan, to see what will be done:
123456789
$ terraform plan
...
Plan: 4 to add, 0 to change, 0 to destroy.
Changes to Outputs:
+ ip = (known after apply)
+ url = (known after apply)
...
I’ve been on the hunt for a hobby dedicated server for a terraform project, where I’m intending to use the libvirt provider and found one awesome provider that offers amazingly great prices.
At oneprovider.com, they offer dedicated servers for great prices and they offer a huge number of locations. So I decided to give them a go and ordered a dedicated server in Amsterdam, Netherlands:
I went for a 4GB DDR3 RAM, Atom C2350 2 Cores CPU with 128GB SSD and 1Gbps unmetered bandwidth for $7.30 a month, which is super cheap and more than enough for a hobby project:
I’ve been using them for the last week and super impressed.
What are we doing
As part of my Terraform project, I would like to experiment with the libvirt provisioner to provision KVM instances, I need a dedicated server with KVM installed, and in this guide we will install KVM and create a dedicated user that we will use with Terraform.
Install KVM
Once your server is provisioned, SSH to your dedicated server and install cpu-checker to ensure that we are able to install KVM:
Create the directory where we will store our vm’s disks:
1
$ mkdir -p /opt/kvm
And apply ownership permissions for our user and group:
1
$ chown -R deploys:libvirt /opt/kvm
I ran into a permission denied issue using terraform and the dedicated user, and to resolve I had to ensure that the security_driver is set to none in /etc/libvirt/qemu.conf:
1
$ vim /etc/libvirt/qemu.conf
and update the following:
1
security_driver = "none"
Then restart libvirtd:
1
$ sudo systemctl restart libvirtd
Test KVM
Switch to the deploys user:
1
$ sudo su - deploys
And list domains using virsh:
123
$ virsh list
Id Name State
----------------------------------------------------
Thank You
That’s it, now we have a KVM host that allows us to provision VM’s. In the next post we will install terraform and the libvirt provisioner for terraform to provision a vm and use ansible to deploy software to our vm.
Thanks for reaching out to me, check out my website or follow me at @ruanbekker on Twitter.
As you can see our local-exec provisioner is issuing the command echo to write the environment variable owner’s value to a file on disk, and the file name is file_ + the null resource’s id.
As we are referencing a variable, we need to define the variable, I will define it in variables.tf:
1
variable "owner" {}
As you can see, I am not defining the value, as I will define the value at runtime.
Initialize
When we initialize terraform, terraform builds up a dependency tree from all the .tf files and downloads any dependencies it requires:
1
$ terraform init
Apply
Run our deployment and pass our variable at runtime:
In this tutorial we will setup a NFS Server using Docker for our development environment.
Host Storage Path
In this example we will be using our host path /data/nfs-storage which will host our storage for our NFS server, which will will mount to the container:
This is a quick post to demonstrate how to use if statements in bash to check if we have the required environment variables in our environment before we continue a script.
Let’s say we require FOO and BAR in our environment before we can continue, we can do this:
1234567891011
#!/usr/bin/env bashif[ -z ${FOO}]||[ -z ${BAR}];thenecho"required environment variables does not exist"exit 1
elseecho"required environment variables are set"# do thingsexit 0
fi
So now if FOO or BAR is not set in our environment, the script will exit with return code 1.
To test it, when we pass no environment variables:
123
$ chmod +x ./update.sh
$ ./update.sh
required environment variables does not exist
If we only pass one environment variable:
12
$ FOO=1 ./update.sh
required environment variables does not exist
And as the result we want, when we pass both required environment variables, we have success:
12
$ FOO=1BAR=2 ./update.sh
required environment variables are set
In the past couple of months i’ve been working a lot with logging, but more specifically logging with loki. As most of my metrics reside in prometheus, I use grafana quite extensively and logging was always the one that stood out a bit as I pushed my logs to elasticsearch and consumed them from grafana. Which worked pretty well, but the maintenance and resource costs was a bit too much for what I was looking for.
And then grafana released Loki, which is like prometheus, but for logs. And that was just super, exactly what I was looking for. For my use case, I was looking for something that can be consumed by grafana as a presentation layer, central based so I can push all sorts of logs, and want a easy way to grep for logs and a bonus would be to have a cli tool.
In this post will be a getting started guide to Loki, we will provision Loki, Grafana and Nginx using Docker to get our environment up and running, so that we can push our nginx container logs to the loki datasource, and access the logs via grafana.
We will then generate some logs so that we can show a couple of query examples using the log query language (LogQL) and use the LogCLI to access our logs via cli.
In a future post, I will demonstrate how to setup Loki for a non-docker deployment.
Some useful information about Loki
Let’s first talk about Loki compared with Elasticsearch, as they are not the same:
Loki does not index the text of the logs, instead grouping entries into streams and index those with labels
Things like full text search engines tokenizes your text into k/v pairs and gets written to an inverted index, which over time in my opinion gets complex to maintain, expensive to scale, storage retention, etc.
Loki is advertised as easy to scale, affordable to operate as it uses DynamoDB for Indexing and S3 for Storage
When using Loki, you may need to forget what you know and look to see how the problem can be solved differently with parallelization. Loki’s superpower is breaking up queries into small pieces and dispatching them in parallel so that you can query huge amounts of log data in small amounts of time.
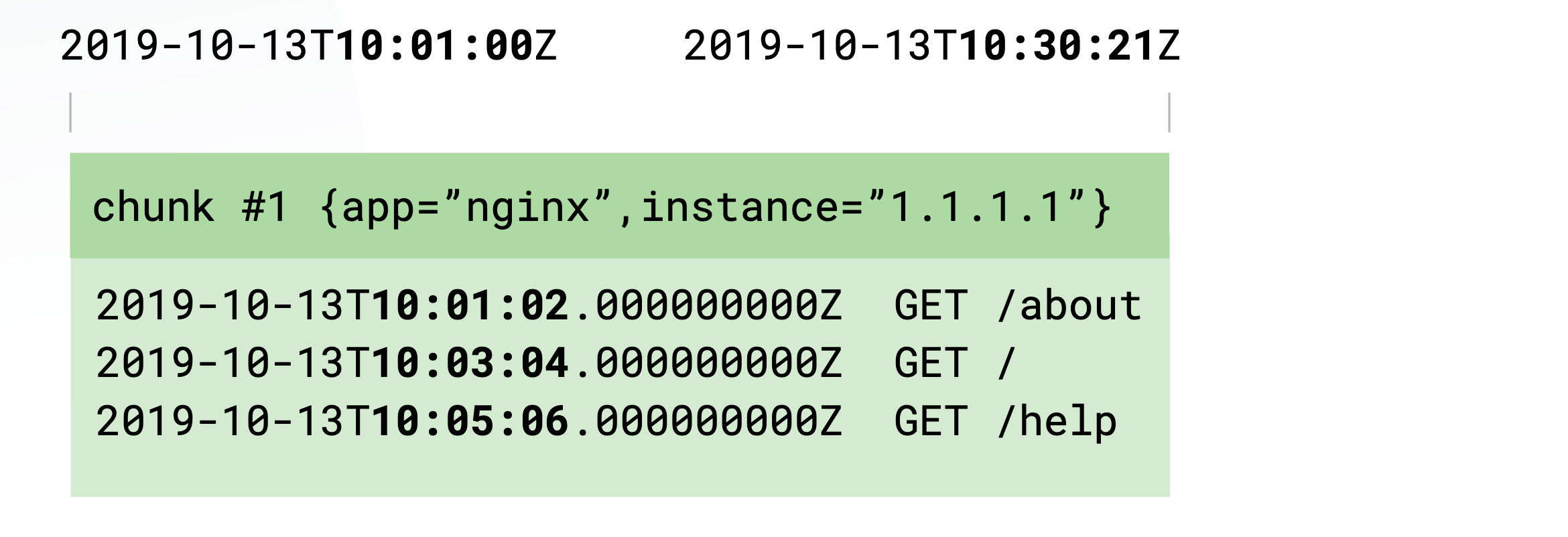
If we look at the Loki Log Model, we can see that the timestamp and the labels are indexed and the content of the logs are not indexed:
A log stream is a stream of log entries with the same exact label set:
For the storage side, inside each chunk, log entries are sorted by timestamp. Loki only indexes minimum and maximum timestamps of a chunk. Storage options support local storage, AWS S3, Google Cloud Storage and Azure
For chunks and querying, chunks are filled per stream and they are flushed of a few criterias such as age and size:
And one of the most important parts are the labels, labels define the stream and therefore its very important.
High cardinality is bad for labels, as something like a IP address can reduce your performance a lot, as it will create a stream for every unique IP label.
Static defined labels such as environment, hostnames are good, you can read more up about it here
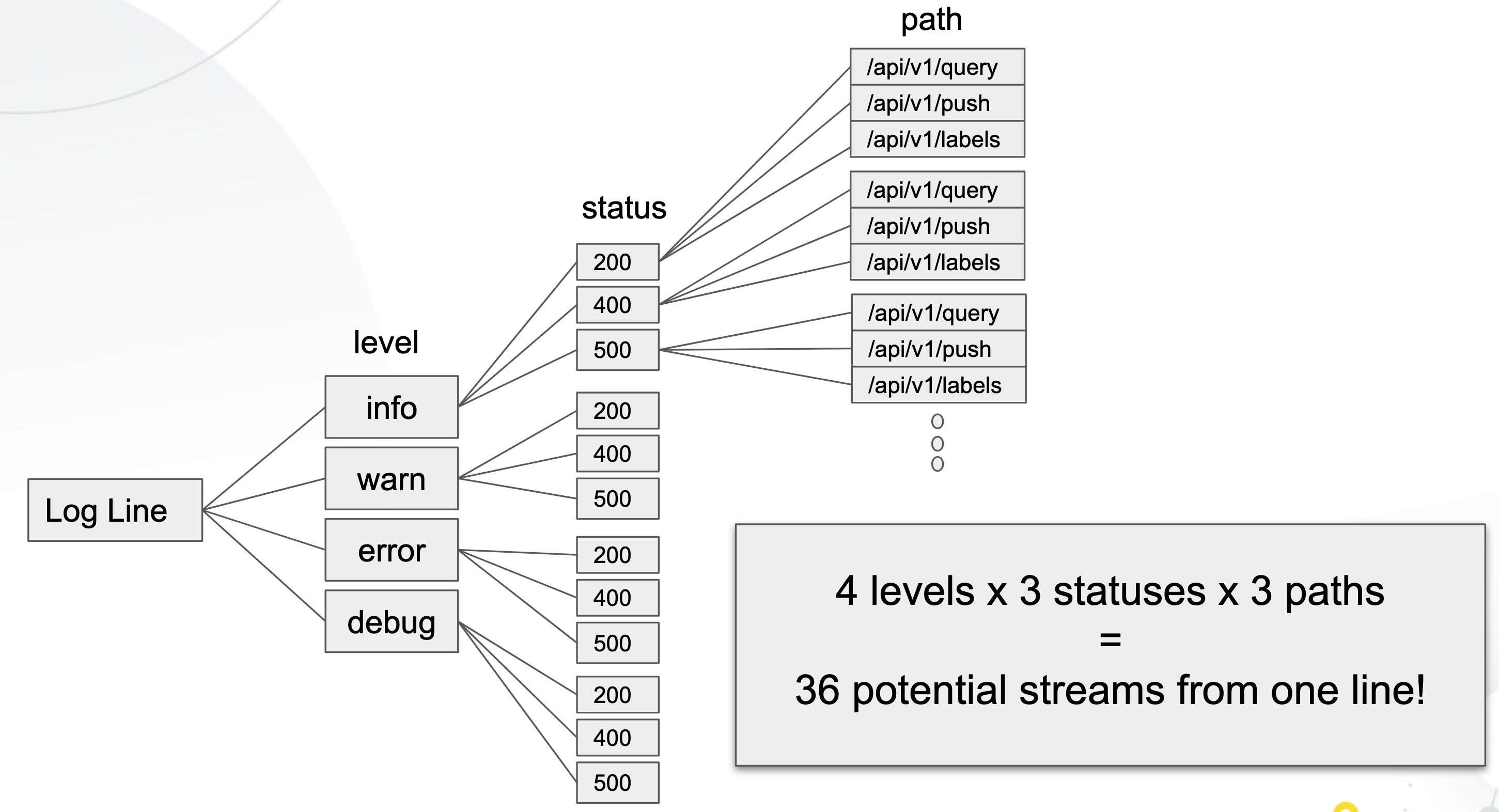
Here is a info graphic on how one log line can be split up into 36 streams:
So with that being said, good labels will be considered as cluster, job, namespace, environment, etc where as bad labels will be things such as userid, ip address, url path, etc
Selecting logstreams with Loki
Selecting logstreams, is done by using label matchers and filter expressions, such as this example:
As you can see loki will be the datasource where we will be pushing our logs to from our nginx container and we are defining our logging section where it should find loki and we are also setting labels to that log stream using loki-external-labels. Then we are using grafana to auto configure the loki datasource from the ./config/datasource.yml section so that we can visualize our logs.
If you don’t want to define the logging section per container, you can always set the defaults using the /etc/docker/daemon.json by following this guide
Let’s boot up our stack:
1
$ docker-compose up
After everything is up, you should be able to access nginx by visiting: http://nginx.localdns.xyz:8000/, after you received a response, visit Grafana on http://grafana.localdns.xyz:3000 using the username and password: admin/admin.
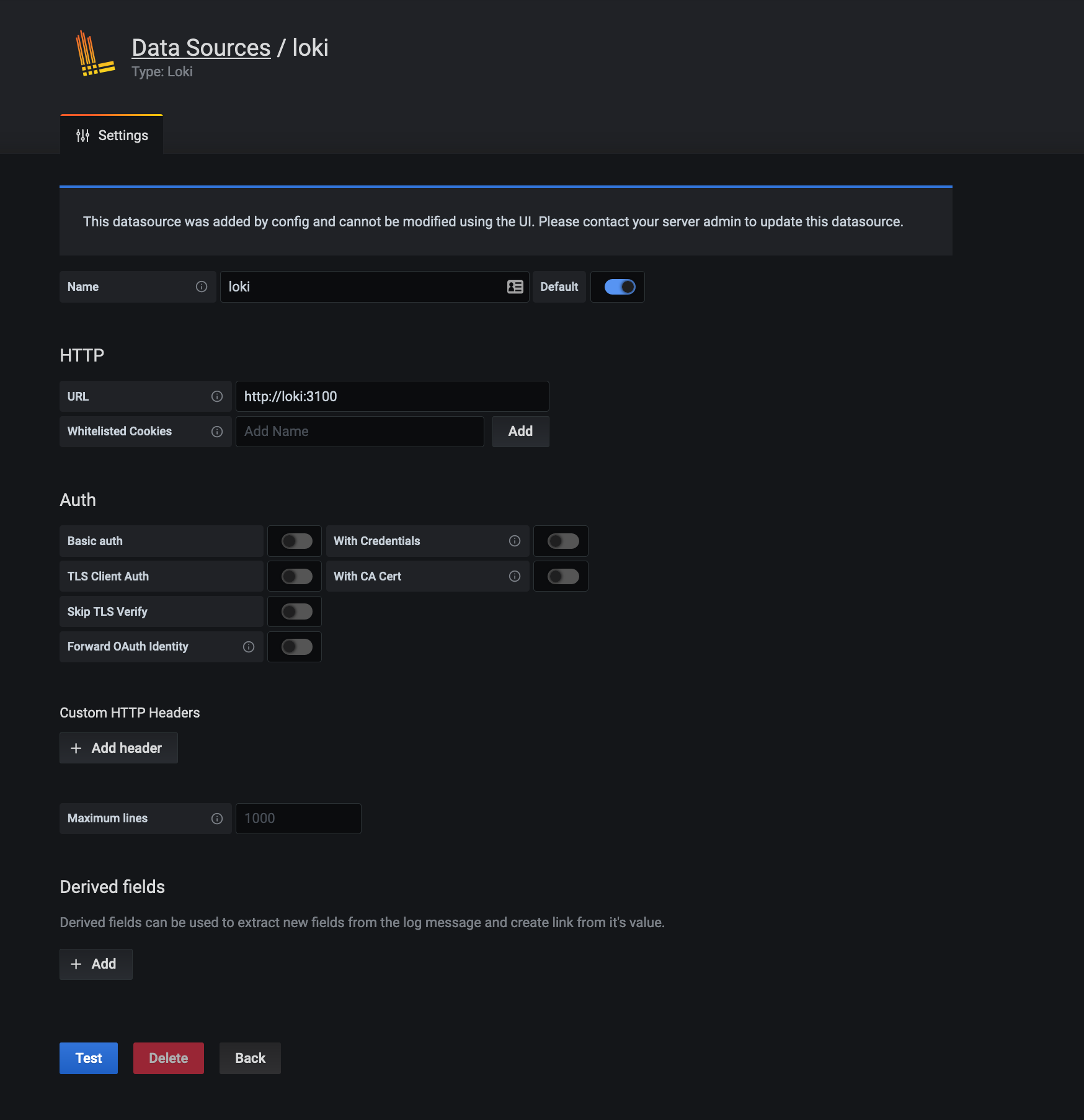
If you head over to datasources, you should see the loki datasource which was provisioned for you:
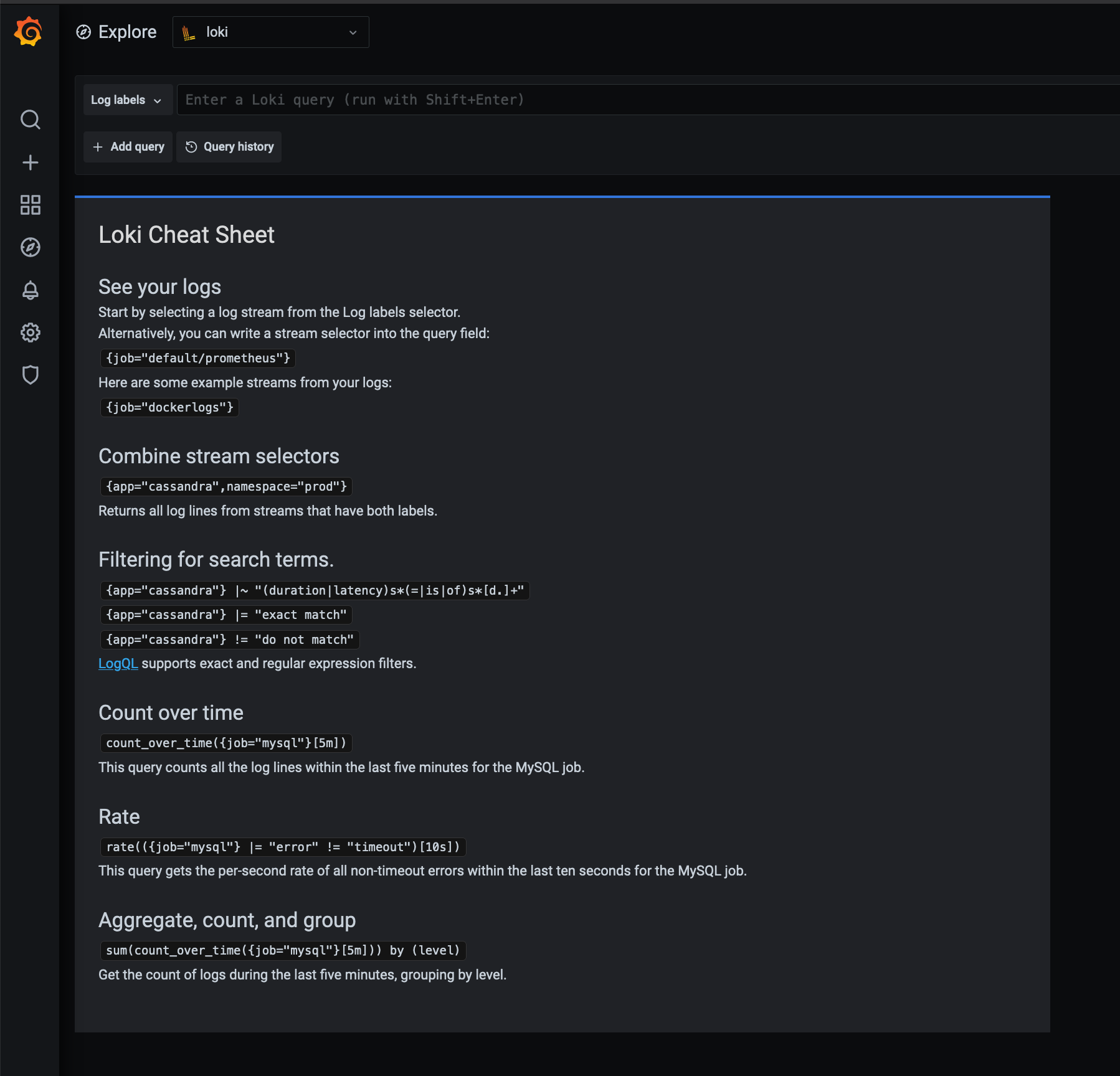
When you head to the left on explore and you select the loki datasource on http://grafana.localdns.xyz:3000/explore you should see the following:
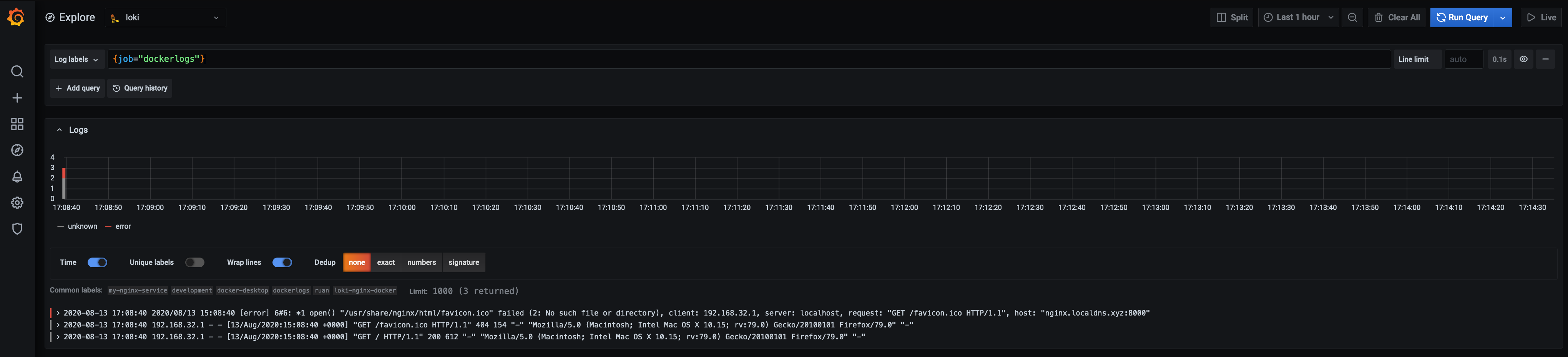
You will see that grafana discovers logstreams with the label job as you can see that our job="dockerlogs" can be seen there. We can either click on it, select the log labels from the left and browse the label we want to select or manually enter the query.
I will be using the query manually:
1
{job="dockerlogs"}
So now we will get all the logs that has that label associated and as you can see, we see our request that we made:
We can see one error due to the favicon.ico that it could not find, but let’s first inspect our first log line:
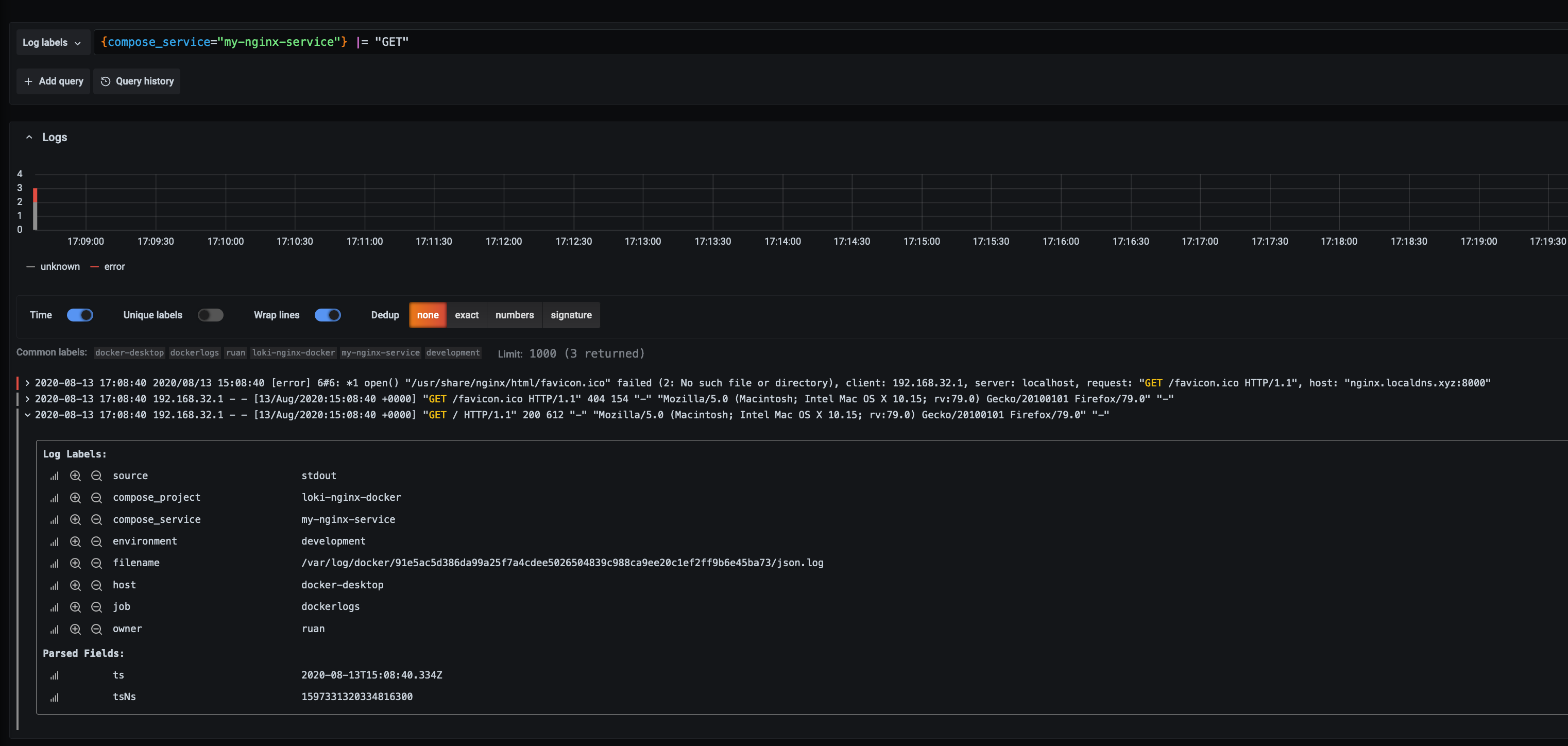
Here we can see the labels assigned to that log event, which we can include in our query, like if we had multiple services and different environments, we can use a query like the following to only see logs for a specific service and environment:
In the example above we used the selectors to select the logs we want to see, now we can use our filter expressions, to “grep” our logs.
Let’s say we want to focus only on one service, and we want to filter for any logs with GET requests, so first we select to service then apply the filter expression:
1
{compose_service="my-nginx-service"} |= "GET"
As you can see we can see the ones we were looking for, we can also chain them, so we want to se GET’s and errors:
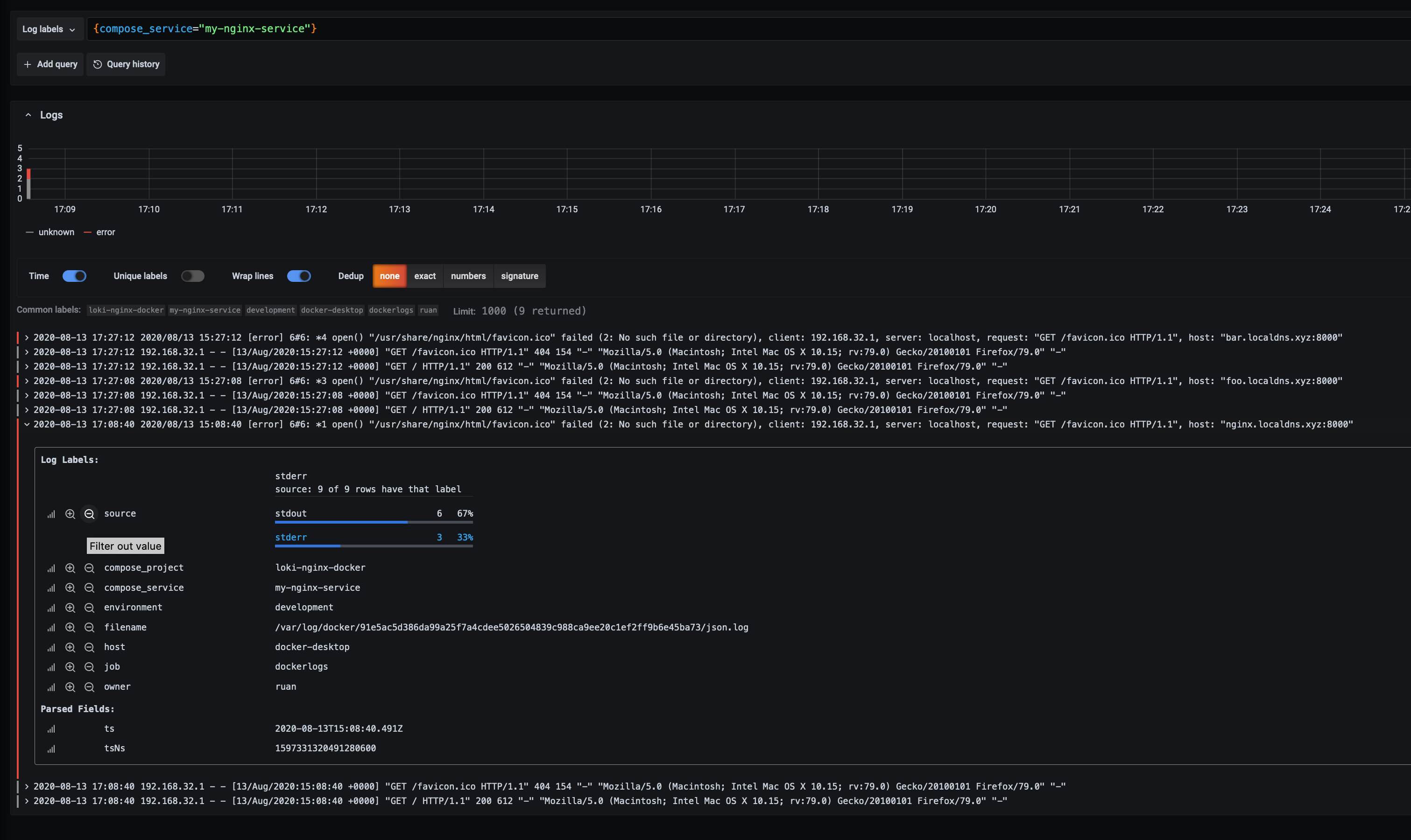
Make two extra get requests to “foo.localdns.xyz:8000” and “bar.localdns.xyz:8000” and then we change the query to say that we only want to see errors and hostnames coming from the 2 requests that we made:
If we expand one of the log lines, we can do a ad-hoc analysis to see the percentage of logs by source for example:
LogCLI
If you prefer the cli to query logs, logcli is the command line client for loki, allows you to query logs from your terminal and has clients for linux, mac and windows.
$ logcli query --help
usage: logcli query [<flags>] <query>
Run a LogQL query.
Flags:
--help Show context-sensitive help (also try --help-long and --help-man).
--version Show application version.
-q, --quiet suppress everything but log lines
--stats show query statistics
-o, --output=default specify output mode [default, raw, jsonl]
-z, --timezone=Local Specify the timezone to use when formatting output timestamps [Local, UTC]
--addr="http://localhost:3100"
Server address. Can also be set using LOKI_ADDR env var.
--username="" Username for HTTP basic auth. Can also be set using LOKI_USERNAME env var.
--password="" Password for HTTP basic auth. Can also be set using LOKI_PASSWORD env var.
--ca-cert="" Path to the server Certificate Authority. Can also be set using LOKI_CA_CERT_PATH env var.
--tls-skip-verify Server certificate TLS skip verify.
--cert="" Path to the client certificate. Can also be set using LOKI_CLIENT_CERT_PATH env var.
--key="" Path to the client certificate key. Can also be set using LOKI_CLIENT_KEY_PATH env var.
--org-id=ORG-ID org ID header to be substituted for auth
--limit=30 Limit on number of entries to print.
--since=1h Lookback window.
--from=FROM Start looking for logs at this absolute time (inclusive)
--to=TO Stop looking for logs at this absolute time (exclusive)
--step=STEP Query resolution step width
--forward Scan forwards through logs.
--no-labels Do not print any labels
--exclude-label=EXCLUDE-LABEL ...
Exclude labels given the provided key during output.
--include-label=INCLUDE-LABEL ...
Include labels given the provided key during output.
--labels-length=0 Set a fixed padding to labels
-t, --tail Tail the logs
--delay-for=0 Delay in tailing by number of seconds to accumulate logs for re-ordering
Args:
<query> eg '{foo="bar",baz=~".*blip"} |~ ".*error.*"'
In this tutorial we will setup a Hugo Blog with the Kiera theme on Linux and will be using Ubuntu for this demonstration, but since Hugo runs on Go, you can run this on Windows, Linux or Mac.
Dependencies
We require git to download the theme from github, so first update your package managers indexes, and install git:
After sourcing the profile we should see the hugo version:
123
$ source ~/.profile
$ hugo version
Hugo Static Site Generator v0.72.0-8A7EF3CF linux/amd64 BuildDate: 2020-05-31T12:07:45Z
Create the Hugo Workspace
Create the directory where we will host our blogs and change into that directory:
12
$ mkdir -p ~/websites
$ cd ~/websites
Create your site with hugo:
123
$ hugo new site awesome-blog
Congratulations! Your new Hugo site is created in /home/ubuntu/websites/awesome-blog.
Visit https://gohugo.io/ for quickstart guide and full documentation.
After config has been applied to ./config.yml and we start our server up again:
1
$ hugo server --theme=kiera --bind=0.0.0.0 --environment development
We should see this:
Create your First Post
Creating the first post:
12
$ hugo new posts/my-first-post.md
/home/ubuntu/websites/awesome-blog/content/posts/my-first-post.md created
Let’s add some sample data to our markdown file that hugo created:
123456789
+++
title = "My First Post"
date = 2020-06-14T15:47:17+02:00
draft = false
tags = ["hugo", "kiera"]
categories = ["hugo-blog"]
+++
-> markdown content here <-
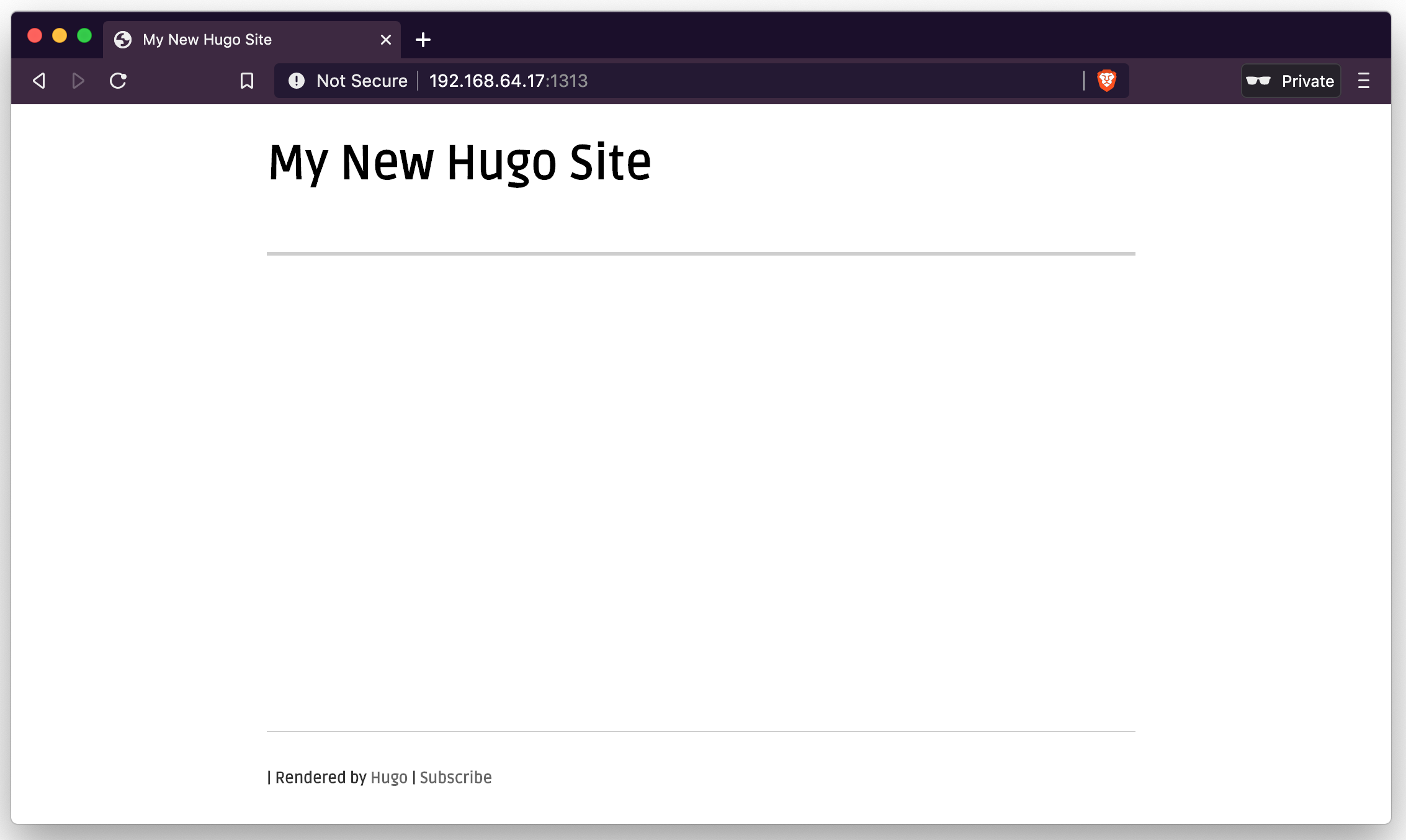
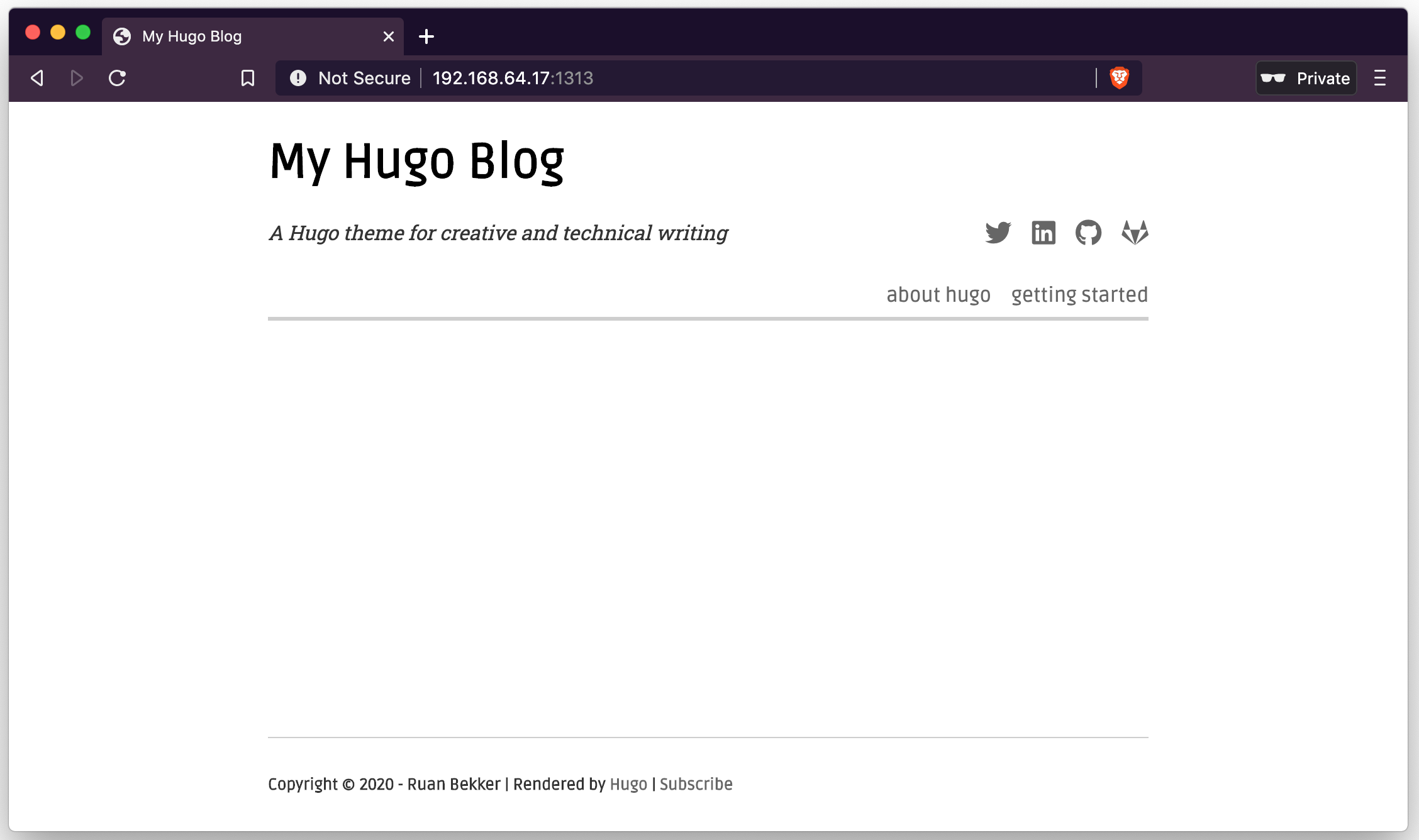
When starting the server up again and viewing the home page:
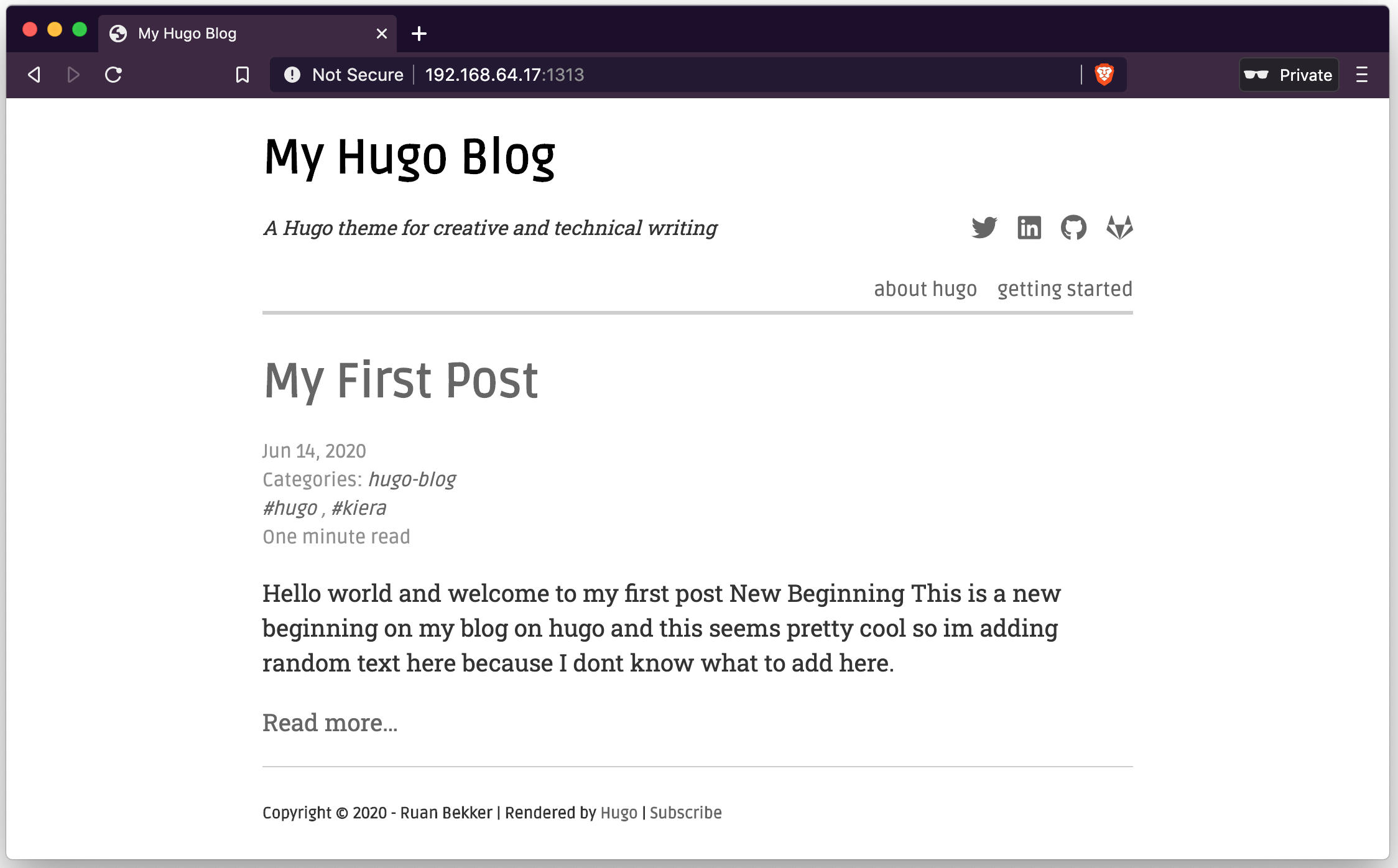
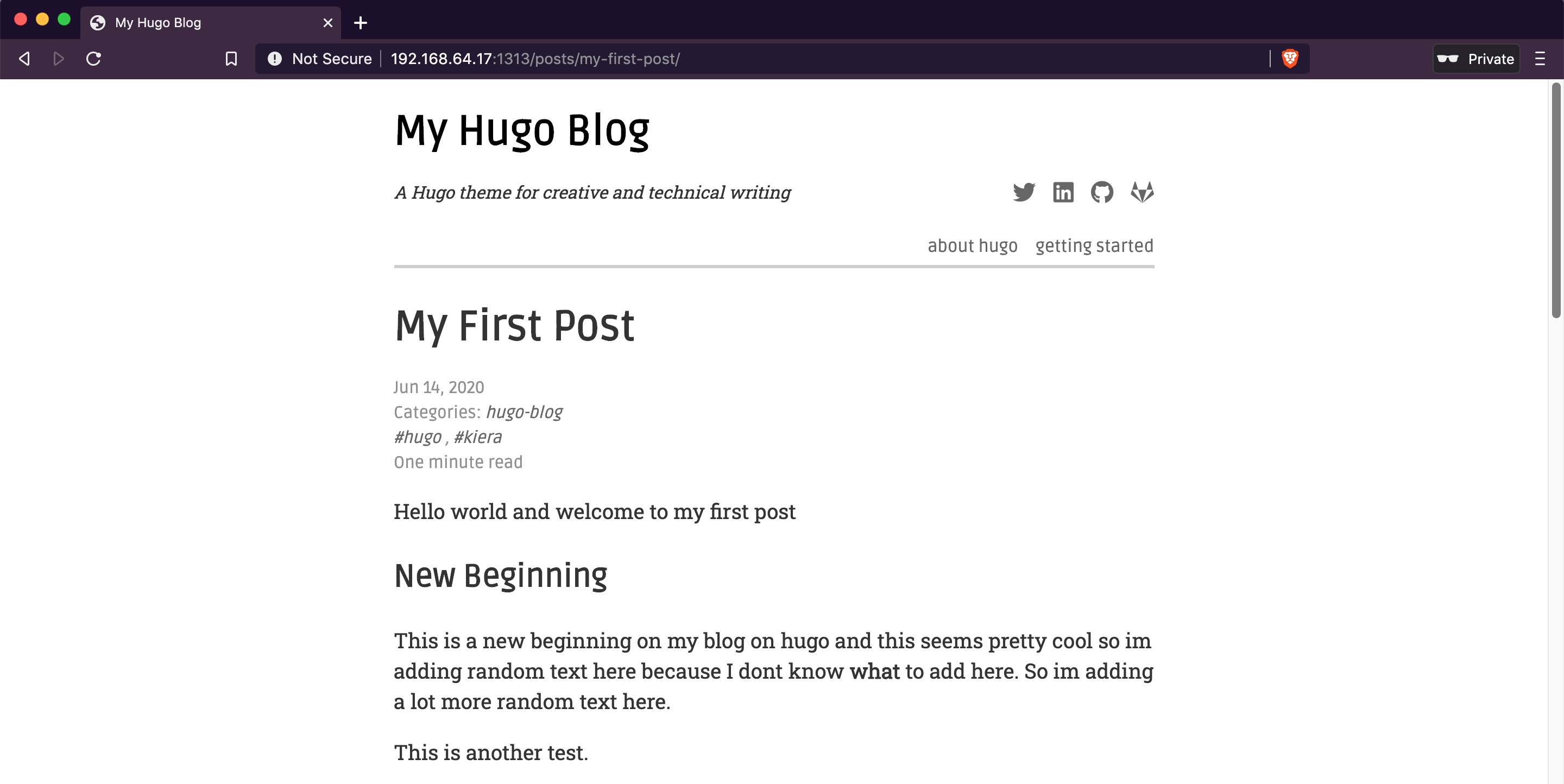
And selecting the post:
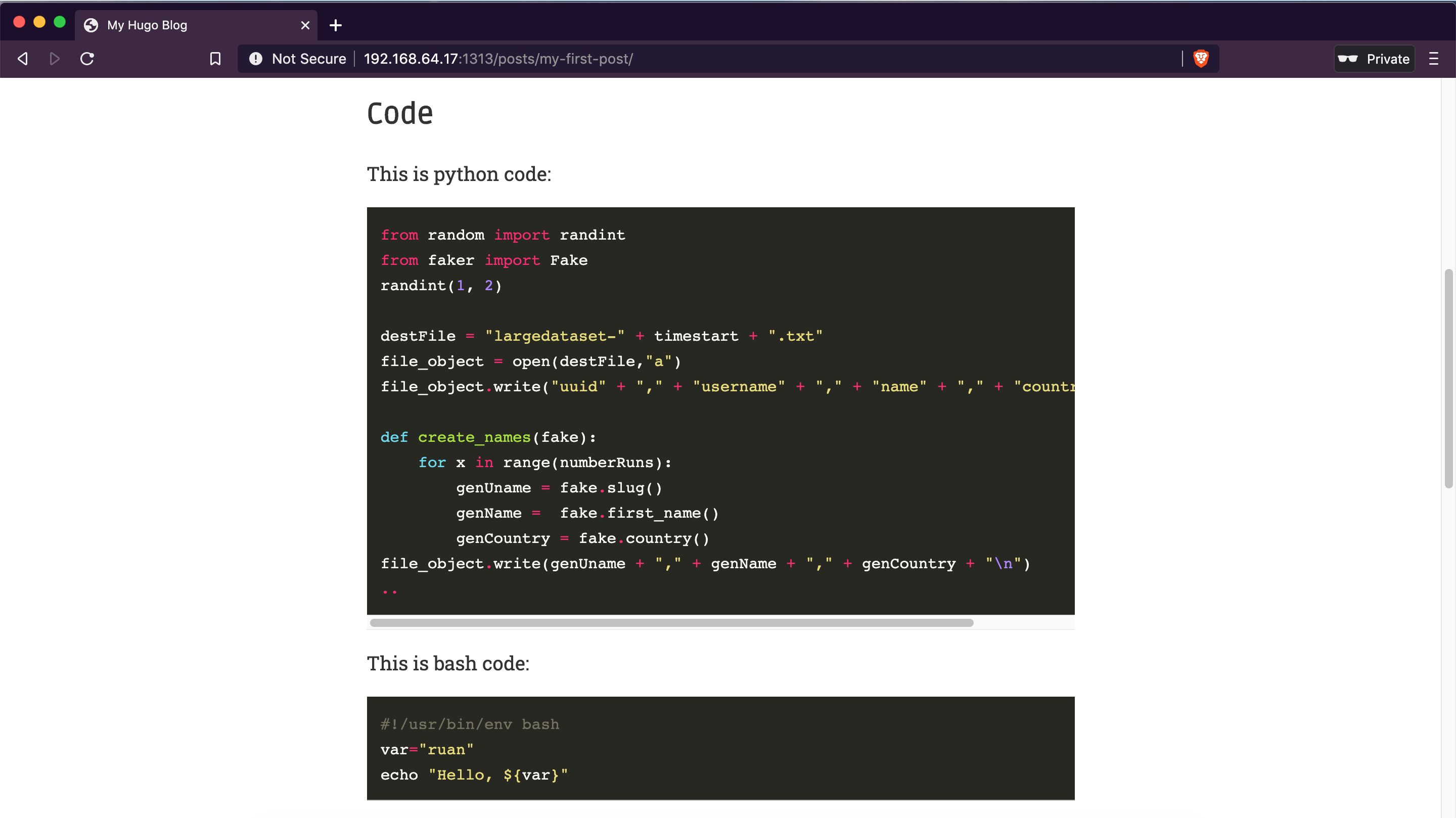
Code snippets:
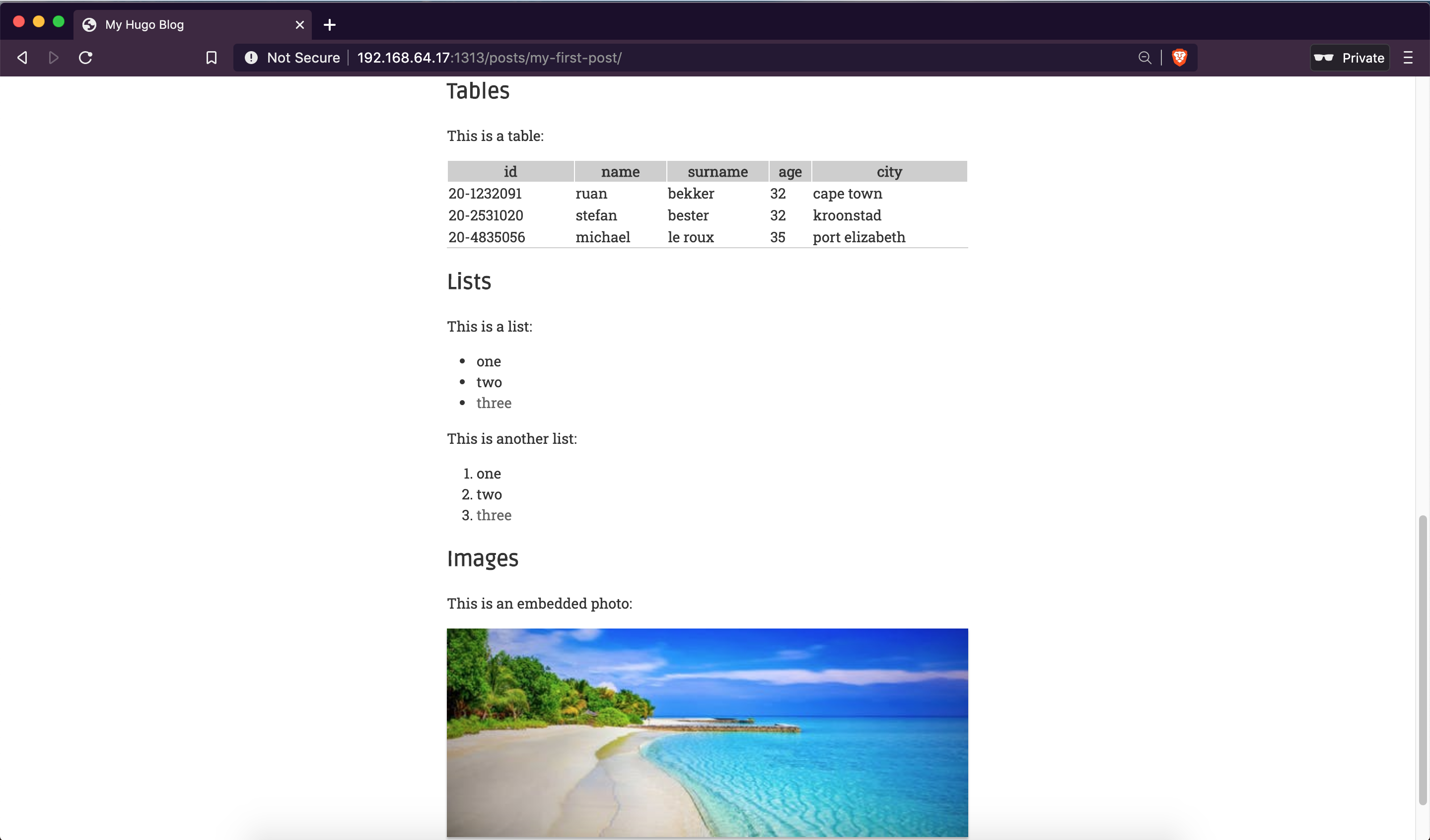
Tables, lists and images:
Creating Pages
For the pages section (about, getting-started), we first create the directory:
1
$ mkdir content/getting-started
Then create the page under the directory:
12
$ hugo new content/getting-started/index.md
content/getting-started/index.md created
The content:
12345678
$ cat content/getting-started/index.md
---
title: "Getting Started"
date: 2020-06-14T16:11:07+02:00
draft: false
---
This is a getting started page
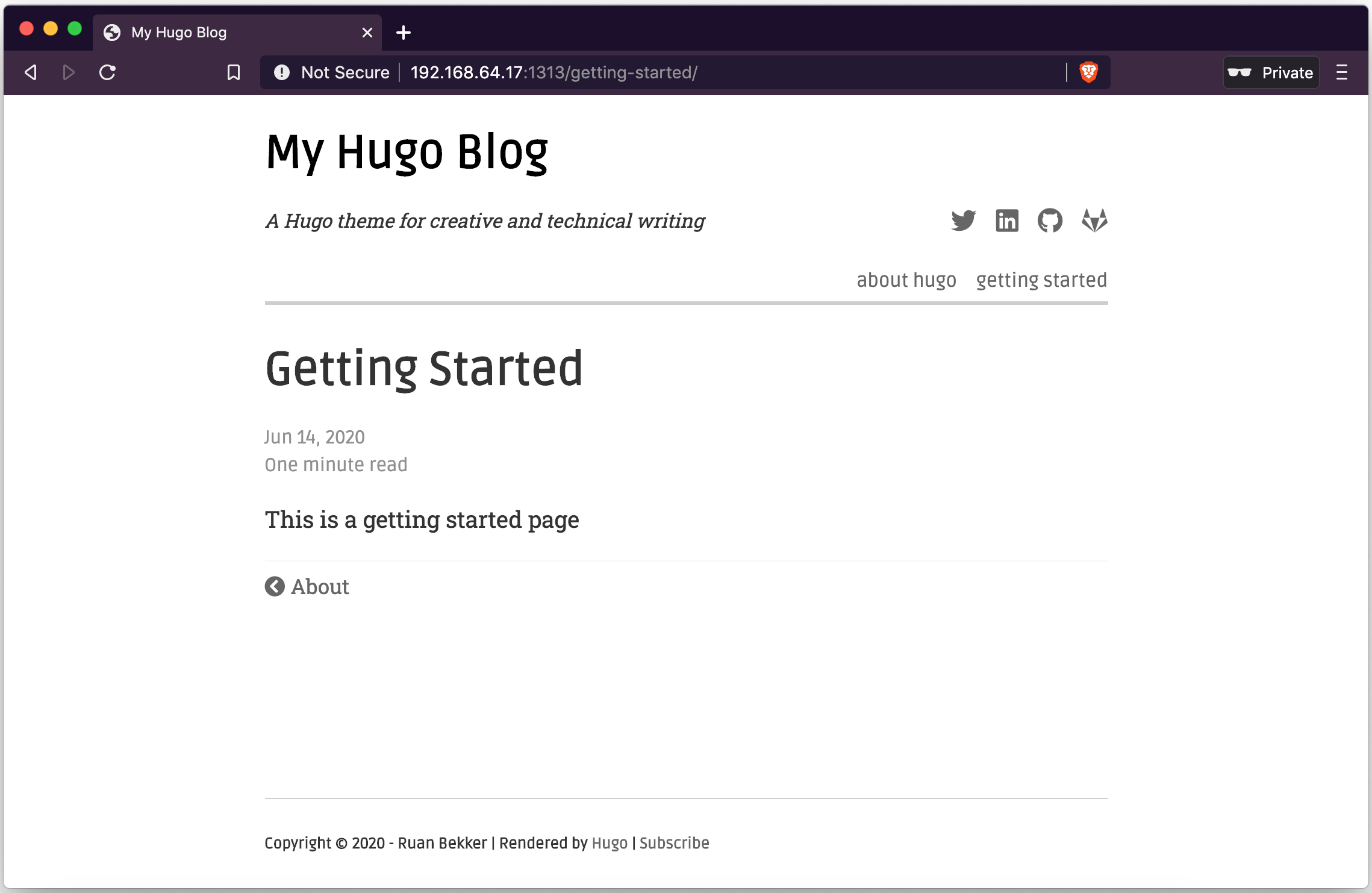
When we start up our server again and select the “getting-started” from the navbar on our home page:
Production Mode
You can set the flags in your main config as well, but running the server in production mode:
12345
$ hugo server \
--baseURL "http://192.168.64.17/" \
--themesDir=themes --theme=kiera \
--bind=0.0.0.0 --port=1313 --appendPort=true \
--buildDrafts --watch --environment production
Thanks
Thanks for reading, feel free to reach out to me on @ruanbekker
I have a dedicated server with LXD installed where I have a bunch of system containers running to host a lot of my playground services, and to access the operating system of those lxc containers, I need to SSH to the LXD host, then exec or ssh into that LXC container.
This became tedious and wanted a way to directly ssh to them, as they don’t have public ip addresses, it’s not possible but found its possible to access them using proxyjump.
1
[you] -> [hypervisor] -> [vm on hypervisor]
First step is to create our ssh key:
1
$ ssh-keygen -t rsa
Add the created public key (~/.ssh/id_rsa.pub) on the hypervisor and the target vm’s ~/.ssh/authorized_key files.
Then create the SSH Config on your local workstation (~/.ssh/config):
1234567891011121314
Host *
StrictHostKeyChecking no
UserKnownHostsFile=/dev/null
Host hypervisor
Hostname hv.domain.com
User myuser
IdentityFile ~/.ssh/id_rsa
Host ctr1
Hostname 10.37.117.132
User root
IdentityFile ~/.ssh/id_rsa
ProxyJump hypervisor
Now accessing our lxc container ctr1, is possible by doing:
1234
$ ssh ctr1
Warning: Permanently added 'x,x' (ECDSA) to the list of known hosts.
Warning: Permanently added '10.37.117.132' (ECDSA) to the list of known hosts.
root@ctr1~ $