I’ve stumbled upon a great bookmarks manager service called Linkding. What I really like about it, it allows you to save your bookmarks, assign tags to it to search for it later, it has chrome and firefox browser extensions, and comes with an API.
Installing Linkding
We will be using Traefik to do SSL termination and host based routing, if you don’t have Traefik running already, you can follow this post to get that set up:
Once you head over to the linkding url that you provided and you logon, you should be able to see something like this:
Creating Bookmarks
When you select “Add Bookmark” and you provide the URL, linkding will retrieve the title and the description and populate it for you, and you can provide the tags (seperated by spaces):
Browser Extensions
To add a browser extension, select “Settings”, then “Integrations”, then you will find the link to the browser extension for Chrome and Firefox:
After you install the browser extension and click on it for the first time, it will ask you to set the Linkding Base URL and API Authentication Token:
You can find that at the bottom of the “Integrations” section:
REST API
You can follow the API Docs for more information, using an example to search for bookmarks with the term “docker”:
{"count":1,"next":null,"previous":null,"results":[{"id":6,"url":"https://www.docker.com/blog/deploying-web-applications-quicker-and-easier-with-caddy-2/","title":"","description":"","website_title":"Deploying Web Applications Quicker and Easier with Caddy 2 - Docker","website_description":"Deploying web apps can be tough, even with leading server technologies. Learn how you can use Caddy 2 and Docker simplify this process.","is_archived":false,"tag_names":["caddy","docker"],"date_added":"2022-05-31T19:11:53.739002Z","date_modified":"2022-05-31T19:11:53.739016Z"}]}
Thank You
Thanks for reading, feel free to check out my website, read my newsletter or follow me at @ruanbekker on Twitter.
In this tutorial, we will demonstrate how to use Python Flask and render_template to use Jinja Templating with our Form. The example is just a ui that accepts a firstname, lastname and email address and when we submit the form data, it renders on a table.
Install Flask
Create a virtual environment and install python flask
As you can see our first route / will render the template in form.html. Our second route /result a couple of things are happening:
If we received a POST method, we will capture the form data
We are then casting it to a dictionary data type
Print the results out of our form data (for debugging)
Then we are passing the result object and the app_version variable to our template where it will be parsed.
When using render_template all html files resides under the templates directory, so let’s first create our base.html file that we will use as a starting point in templates/base.html:
1
mkdirtemplates
Then in your templates/base.html:
In our templates/form.html we have our form template, and you can see we are referencing our base.html in our template to include the first bit:
Then our last template templates/result.html is used when we click on submit, when the form data is displayed in our table:
This is a quick demonstration on how to use prometheus relabel configs, when you have scenarios for when example, you want to use a part of your hostname and assign it to a prometheus label.
Prometheus Relabling
Using a standard prometheus config to scrape two targets:
- ip-192-168-64-29.multipass:9100
- ip-192-168-64-30.multipass:9100
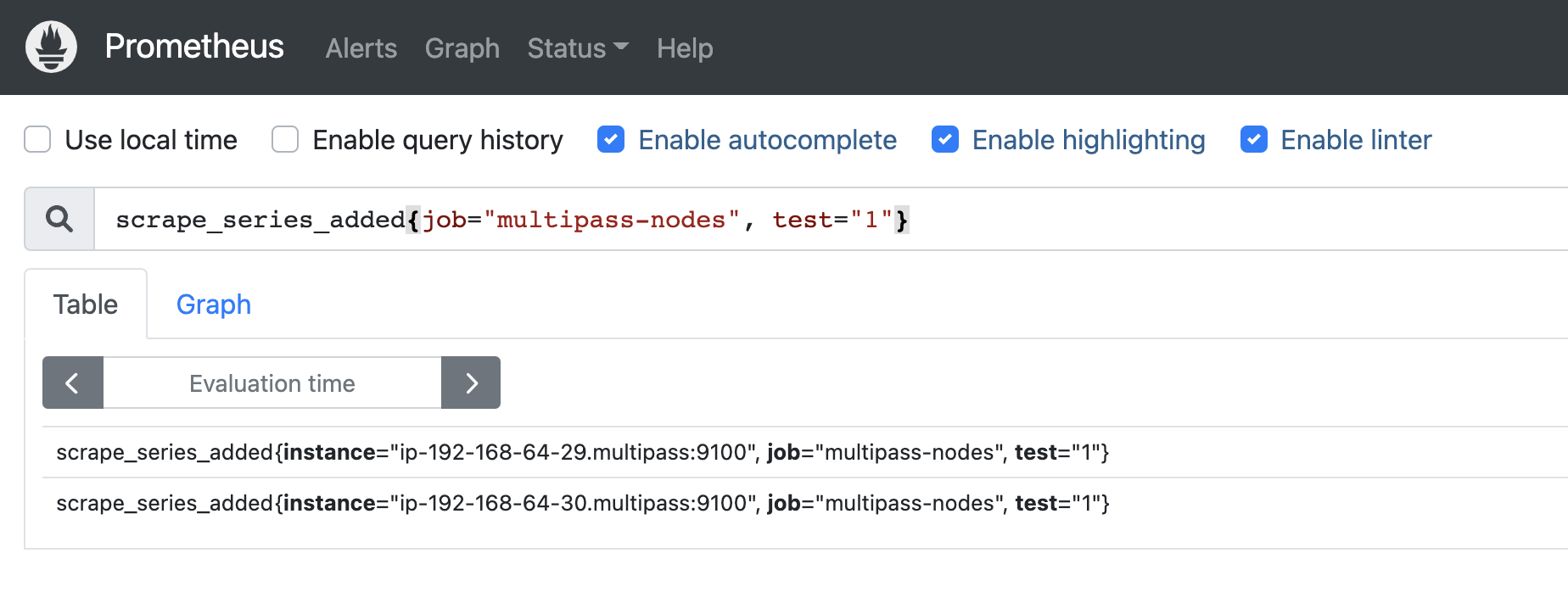
When we want to relabel one of the source the prometheus internal labels, __address__ which will be the given target including the port, then we apply regex: (.*) to catch everything from the source label, and since there is only one group we use the replacement as ${1}-randomtext and use that value to apply it as the value of the given target_label which in this case is for randomlabel, which will be in this case:
In this case we want to relabel the __address__ and apply the value to the instance label, but we want to exclude the :9100 from the __address__ label:
On AWS EC2 you can make use of the ec2_sd_config where you can make use of EC2 Tags, to set the values of your tags to prometheus label values.
In this scenario, on my EC2 instances I have 3 tags:
- Key: PrometheusScrape, Value: Enabled
- Key: Name, Value: pdn-server-1
- Key: Environment, Value: dev
In our config, we only apply a node-exporter scrape config to instances which are tagged PrometheusScrape=Enabled, then we use the Name tag, and assign it’s value to the instance tag, and the similarly we assign the Environment tag value to the environment promtheus label value.
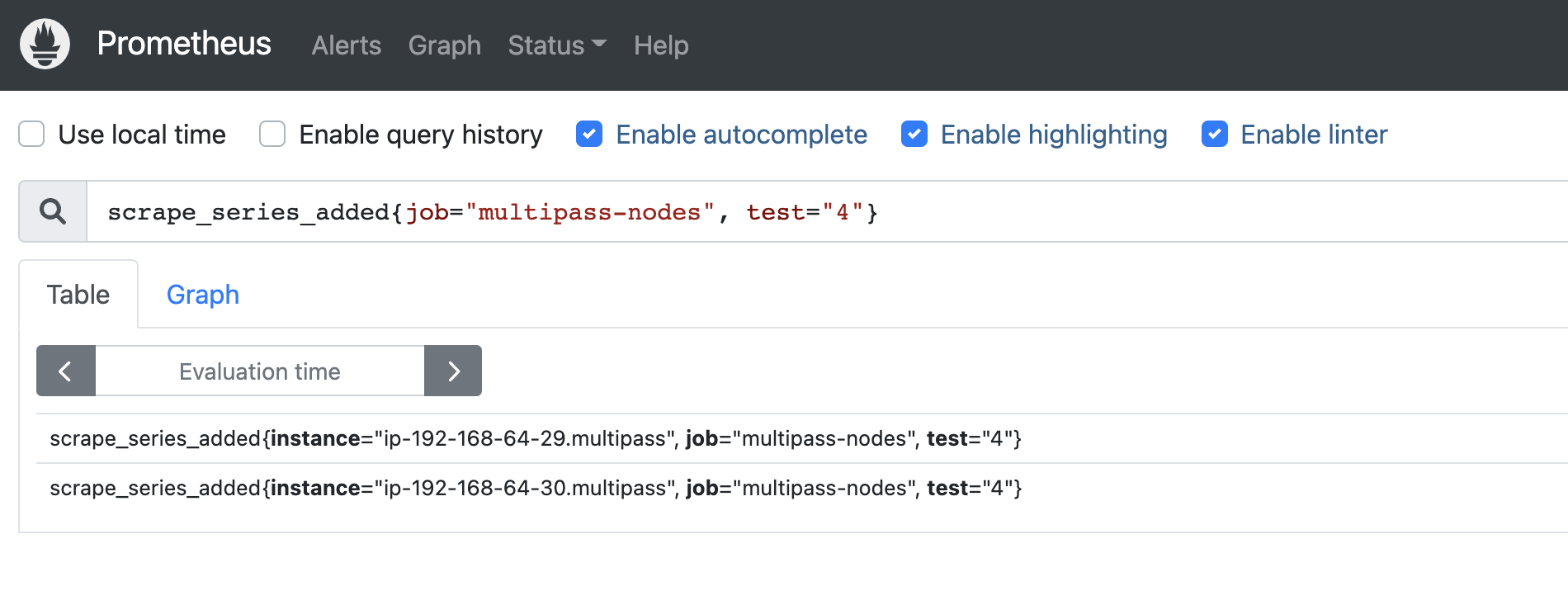
Because this prometheus instance resides in the same VPC, I am using the __meta_ec2_private_ip which is the private ip address of the EC2 instance to assign it to the address where it needs to scrape the node exporter metrics endpoint:
In this tutorial we will be creating a AWS Lambda Python Layer that will include the Python Requests package and we will compile the package with Docker and the LambCI image.
Getting Started
First we will create the directory where we will store the intermediate data:
12
$ mkdir lambda-layers
$ cd lambda-layers
Then we will create the directory structure, as you can see I will be using the python 3.8 runtime:
12
$ mkdir -p requests/python/lib/python3.8
$ cd requests
Write the dependencies to the requirements file:
1
$ echo"requests" > requirements.txt
Install dependencies locally using docker, where we will be using the lambci/lambda:build-python3.8 iamge and we are mounting our current working directory to /var/task inside the container, and then we will be running the command pip install -r requirements.txt -t python/lib/python3.7/site-packages/; exit inside the container, which will essentially dump the content to our working directory:
123
$ docker run -v $PWD:/var/task \ lambci/lambda:build-python3.8 \ sh -c "pip install -r requirements.txt -t python/lib/python3.8/site-packages/; exit"
Zip up the deployment package that we will push to AWS Lambda Layers:
1
$ zip -r package.zip python > /dev/null
Publish the layer using the aws cli tools, by specifying the deployment package, the compatible runtime and a identifier:
In this tutorial we will customize the vim editor, by adding the molokai color scheme, change a couple of basic settings (more suited for my preference - not too much) and add a couple of plugins that will change the look to something like this:
About Vim
vim has always been my favorite linux text editor, which is super powerful and highly customizable
Install Vim
Update indexes:
1
sudo apt update
Install vim:
1
sudo apt install vim -y
Color Scheme
To find all existing vim color schemes installed:
1
find /usr/share/vim/vim*/colors/ -type f -name "*.vim"
By default our color scheme will look like this when we create foo.py:
When we hit the “esc” button, and enter :colorscheme molokai we can change the colorscheme to molokai, and then we should have the following:
To persist these changes, open up ~/.vimrc and paste the following as a starter:
12
colorscheme molokai
syntax on
Now when we open up foo.py we will see that it defaults to the molokai color scheme.
Vim Configuration
Everyone has their own personal preference on vim configs, but I like to keep mine basic, and this is the content of my ~/.vimrc:
123456789101112131415
colorscheme molokai
syntax on
set mouse-=a
filetype on
filetype indent plugin on
set noexpandtab " tabs ftwset smarttab " tab respects 'tabstop', 'shiftwidth', and 'softtabstop'set tabstop=4" the visible width of tabsset softtabstop=4 " edit as if the tabs are 4 characters wide
set shiftwidth=4" number of spaces to use for indent and unindentset shiftround " round indent to a multiple of 'shiftwidth'autocmd FileType yml setlocal ts=2sts=2sw=2 expandtab
autocmd FileType yaml setlocal ts=2sts=2sw=2 expandtab
"" https://github.com/VundleVim/Vundle.vim
set nocompatible
filetype off
" set the runtime path to include Vundle and initializeset rtp+=~/.vim/bundle/Vundle.vimcall vundle#begin()" alternatively, pass a path where Vundle should install plugins
"call vundle#begin('~/some/path/here')"let Vundle manage Vundle, required
Plugin 'VundleVim/Vundle.vim'" The following are examples of different formats supported." Keep Plugin commands between vundle#begin/end.
" plugin on GitHub repoPlugin 'tpope/vim-fugitive'" plugin from http://vim-scripts.org/vim/scripts.html
" Plugin 'L9'" Git plugin not hosted on GitHub
Plugin 'git://git.wincent.com/command-t.git'" git repos on your local machine (i.e. when working on your own plugin)" Plugin 'file:///home/gmarik/path/to/plugin'" The sparkup vim script is in a subdirectory of this repo called vim." Pass the path to set the runtimepath properly.
Plugin 'rstacruz/sparkup', {'rtp': 'vim/'}" Install L9 and avoid a Naming conflict if you've already installed a" different version somewhere else.
" Plugin 'ascenator/L9', {'name': 'newL9'}" All of your Plugins must be added before the following line
call vundle#end()" requiredfiletype plugin indent on " required
" To ignore plugin indent changes, instead use:"filetype plugin on
"" Brief help" :PluginList - lists configured plugins" :PluginInstall - installs plugins; append `!` to update or just :PluginUpdate
" :PluginSearch foo - searches for foo; append `!` to refresh local cache" :PluginClean - confirms removal of unused plugins; append `!` to auto-approve removal
"" see :h vundle for more details or wiki for FAQ
" Put your non-Plugin stuff after this line" colorscheme duo-mini
" sets color themescolorscheme molokaisyntax on" sets the filename at the bottom
set laststatus=2
" https://github.com/itchyny/lightline.vimPlugin 'itchyny/lightline.vim'" https://github.com/Shougo/neobundle.vim
" Note: Skip initialization for vim-tiny or vim-small.if 0 | endifif &compatible set nocompatible " Be iMproved
endif
" Required:set runtimepath+=~/.vim/bundle/neobundle.vim/" Required:
call neobundle#begin(expand('~/.vim/bundle/'))" Let NeoBundle manage NeoBundle" Required:
NeoBundleFetch 'Shougo/neobundle.vim'" My Bundles here:" Refer to |:NeoBundle-examples|.
" Note: You don't set neobundle setting in .gvimrc!NeoBundle 'itchyny/lightline.vim'call neobundle#end()" Required:
filetype plugin indent on
" If there are uninstalled bundles found on startup," this will conveniently prompt you to install them.
NeoBundleCheck
" https://github.com/junegunn/vim-plug" Specify a directory for plugins
" - For Neovim: stdpath('data') . '/plugged'" - Avoid using standard Vim directory names like 'plugin'call plug#begin('~/.vim/plugged')" Make sure you use single quotes" Shorthand notation; fetches https://github.com/junegunn/vim-easy-align
Plug 'junegunn/vim-easy-align'" Any valid git URL is allowedPlug 'https://github.com/junegunn/vim-github-dashboard.git'" Multiple Plug commands can be written in a single line using | separators
"Plug 'SirVer/ultisnips' | Plug 'honza/vim-snippets'" On-demand loading
Plug 'scrooloose/nerdtree', {'on': 'NERDTreeToggle'}Plug 'tpope/vim-fireplace', {'for': 'clojure'}" Using a non-master branchPlug 'rdnetto/YCM-Generator', { 'branch': 'stable' }" Using a tagged release; wildcard allowed (requires git 1.9.2 or above)Plug 'fatih/vim-go', {'tag': '*'}" Plugin optionsPlug 'nsf/gocode', { 'tag': 'v.20150303', 'rtp': 'vim' }" Plugin outside ~/.vim/plugged with post-update hook
Plug 'junegunn/fzf', {'dir': '~/.fzf', 'do': './install --all'}" Unmanaged plugin (manually installed and updated)Plug '~/my-prototype-plugin'Plug 'itchyny/lightline.vim'" Initialize plugin system
call plug#end()" sets the filename as the title up top"set title
" let g:airline#extensions#tabline#enabled = 1set noexpandtab " tabs ftw
set smarttab " tab respects 'tabstop', 'shiftwidth', and 'softtabstop'set tabstop=4 " the visible width of tabs
set softtabstop=4" edit as if the tabs are 4 characters wideset shiftwidth=4 " number of spaces to use for indent and unindent
set shiftround " round indent to a multiple of 'shiftwidth'autocmd FileType yml setlocal ts=2sts=2sw=2 expandtab
autocmd FileType yaml setlocal ts=2sts=2sw=2 expandtab
First we will create a basic discord bot that will greet the message sender, and then we will create a Minecraft Bot, that will enable us to do the following:
12345
:: Bot Usage ::
!mc help : shows help
!mc serverusage : shows system load in percentage
!mc serverstatus : shows if the server is online or offline
!mc whoisonline : shows who is online at the moment
Let’s get into it.
Dependencies
Create a python virtual environment and install the dependent packages:
Once you create the application you will get a screen to upload a logo, provide a description and most importantly get your application id as well as your public key:
Then select the Bot section:
Then select “Add Bot”:
Select OAuth2 and select the “bot” scope:
At the bottom of the page it will provide you with a URL that looks something like:
Paste the link in your browser and authorize the bot to your server of choice:
Then click authorize, and you should see your bot appearing on Discord:
Developing the Discord Bot
Now we will be building our python discord bot, head back to the “Bot” section and select “Reset Token”, then copy and store the token value to a file .env:
1
DISCORD_TOKEN=xxxxxxxxx
So in our current working directory, we should have a file .env with the following content:
For this demonstration, I will create a private channel in discord called minecraft-test and add the bot MinecraftBot to the channel (this is only for testing, after testing you can add your bot to your other channels for other people to use):
For our first test, a basic bot, where we would like to type hello and the bot should greet us by our username, in our mc_discord_bot.py file we will have:
12345678910111213141516171819202122232425
importdiscordimportosfromdotenvimportload_dotenvBOT_NAME="MinecraftBot"load_dotenv()DISCORD_TOKEN=os.getenv("DISCORD_TOKEN")bot=discord.Client()@bot.eventasyncdefon_ready():print(f'{bot.user} has logged in.')@bot.eventasyncdefon_message(message):ifmessage.author==bot.user:returnifmessage.content=='hello':awaitmessage.channel.send(f'Hey {message.author}')ifmessage.content=='goodbye':awaitmessage.channel.send(f'Goodbye {message.author}')bot.run(DISCORD_TOKEN)
Then run the bot:
12
$pythonmc_discord_bot.pyMinecraftBothasloggedin.
And when we type hello and goodbye you can see our bot responds on those values:
Now that we tested our bot, we can clear the mc_discord_bot.py and write our minecraft bot, the requirements of this bot is simple, but we would like the following:
use the command !mc to trigger our bot and subcommands for what we want
able to see who is playing minecraft on our server at the moment
able to get the status if the minecraft server is online
able to get the server load percentage (as the bot runs on the minecraft server)
importdiscordfromdiscord.extimportcommandsimportrequestsimportosfromdotenvimportload_dotenvimportrandomimportmultiprocessing# VariablesBOT_NAME="MinecraftBot"load_dotenv()DISCORD_TOKEN=os.getenv("DISCORD_TOKEN")minecraft_server_url="lightmc.fun"# this is just an example, and you should use your own minecraft serverbot_help_message=""":: Bot Usage ::`!mc help` : shows help`!mc serverusage` : shows system load in percentage`!mc serverstatus` : shows if the server is online or offline`!mc whoisonline` : shows who is online at the moment"""available_commands=['help','serverusage','serverstatus','whoisonline']# Set the bot command prefixbot=commands.Bot(command_prefix="!")# Executes when the bot is ready@bot.eventasyncdefon_ready():print(f'{bot.user} succesfully logged in!')# Executes whenever there is an incoming message event@bot.eventasyncdefon_message(message):print(f'Guild: {message.guild.name}, User: {message.author}, Message: {message.content}')ifmessage.author==bot.user:returnifmessage.content=='!mc':awaitmessage.channel.send(bot_help_message)if'whosonline'inmessage.content:print(f'{message.author} used {message.content}')awaitbot.process_commands(message)# Executes when the command mc is used and we trigger specific functions# when specific arguments are caught in our if statements@bot.command()asyncdefmc(ctx,arg):ifarg=='help':awaitctx.send(bot_help_message)ifarg=='serverusage':cpu_count=multiprocessing.cpu_count()one,five,fifteen=os.getloadavg()load_percentage=int(five/cpu_count*100)awaitctx.send(f'Server load is at {load_percentage}%')ifarg=='serverstatus':response=requests.get(f'https://api.mcsrvstat.us/2/{minecraft_server_url}').json()server_status=response['online']ifserver_status==True:server_status='online'awaitctx.send(f'Server is {server_status}')ifarg=='whoisonline':response=requests.get('https://api.mcsrvstat.us/2/{minecraft_server_url}').json()players_status=response['players']ifplayers_status['online']==0:players_online_message='No one is online'ifplayers_status['online']==1:players_online_username=players_status['list'][0]players_online_message=f'1 player is online: {players_online_username}'ifplayers_status['online']>1:po=players_status['online']players_online_usernames=players_status['list']joined_usernames=", ".join(players_online_usernames)players_online_message=f'{po} players are online: {joined_usernames}'awaitctx.send(f'{players_online_message}')bot.run(DISCORD_TOKEN)
And now we can start our bot:
1
$ python mc_discord_bot.py
And we can run our help command:
1
!mc help
Which will prompt our help message, and then test out the others:
Resources
Thank you to the following authors, which really helped me doing this:
I’ve started a brand new Discord server, not much happening at the moment, but planning to share and distribute tech content and a place for like minded people to hang out. If that’s something you are interested in, feel free to join on this link
In this tutorial we will be creating a ansible role, publish our ansible role to github, then we will install the role locally and create a ansible playbook to use the ansible role.
The source code for this blog post will be available on my github repository.
Now your ansible role should be commited and visible in git.
SSH Config Client Side
I will be referencing the git source url via SSH, and since I am using my default ssh key, the ssh config isn’t really needed, but if you are using a different version control system, with different ports or different ssh keys, the following ssh config snippet may be useful:
If you won’t be using SSH as the source url in your ansible setup for your role, you can skip the SSH setup.
Installing the Ansible Role from Git
When installing roles, ansible installs them by default under: ~/.ansible/roles, /usr/share/ansible/roles or /etc/ansible/roles.
From our previous steps, we still have the ansible role content locally (not under the default installed directory), so by saying installing the role kinda sounds like we are doing double the work. But the intention is that you have your ansible role centralized and versioned on git, and on new servers or workstations where you want to consume the role from, that specific role, won’t be present on that source.
To install the role from Git, we need to populate the requirements.yml file:
12
$ mkdir ~/my-project$ cd ~/my-project
The requirements file is used to define where our role is located, which version and the type of version control, the requirements.yml:
For other variations of using the requirements file, you can have a look at their documentation
Then install the ansible role from our requirements file (I have used --force to overwrite my current one while testing):
12345
$ ansible-galaxy install -r requirements.yml --forceStarting galaxy role install process- changing role ssh_config from main to main- extracting ssh_config to /Users/ruan/.ansible/roles/ssh_config- ssh_config (main) was installed successfully
Ansible Playbook
Define the ansible playbook to use the role that we installed from git, in a file called playbook.yml:
In this tutorial I will demonstrate how to use Terraform (a Infrastructure as Code Tool), to provision a AWS EC2 Instance and the source code that we will be using in this tutorial will be published to my terraformfiles github repository.
Requirements
To follow along this tutorial, you will need an AWS Account and Terraform installed
You will notice that I am defining my profile name default from the ~/.aws/credentials credential provider in order for terraform to authenticate with AWS.
Next I am defining the main.tf which will be the file where we define our aws resources:
variable "default_tags"{default={Environment="test"Owner="ruan.bekker"Project="terraform-blogpost"CostCenter="engineering"ManagedBy="terraform"}}variable "aws_region"{type= string
default="eu-west-1"description="the region to use in aws"}variable "vpc_id"{type= string
description="the vpc to use"}variable "ssh_keyname"{type= string
description="ssh key to use"}variable "subnet_id"{type= string
description="the subnet id where the ec2 instance needs to be placed in"}variable "instance_type"{type= string
default="t3.nano"description="the instance type to use"}variable "project_id"{type= string
default="terraform-blogpost"description="the project name"}variable "ebs_root_size_in_gb"{type= number
default= 10
description="the size in GB for the root disk"}variable "environment_name"{type= string
default="dev"description="the environment this resource will go to (assumption being made theres one account)"}
The next file is our locals.tf which just concatenates our project id and environment name:
Then our outputs.tf for the values that terraform should output:
1234567891011121314151617
output "id"{description="The ec2 instance id"value= aws_instance.ec2.id
sensitive=false}output "ip"{description="The ec2 instance public ip address"value= aws_instance.ec2.public_ip
sensitive=false}output "subnet_id"{description="the subnet id which will be used"value= var.subnet_id
sensitive=false}
Then lastly our terraform.tfvars, which you will need to supply your own values to match your AWS Account:
Now that all our configuration is in place, we need to intialize terraform by downloading the providers:
1
terraform init
Once the terraform init has completed, we can run a terraform plan which will show us what terraform will do. Since the terraform.tfvars are the default file for variables, we don’t have to specify the name of the file, but since I want to be excplicit, I will include it (should you want to change the file name):
1
terraform plan -var-file="terraform.tfvars"
Now it’s a good time to review what terraform wants to action by viewing the plan output, once you are happy you can deploy the changes by running a terraform apply:
1
terraform apply -var-file="terraform.tfvars"
Optional: You can override variables by either updating the terraform.tfvars or you can append them with terraform apply -var-file="terraform.tfvars" -var="ssh_key=default_key", a successful output should show something like this:
You can access the instance by SSH'ing to the IP that was returned by the output as well as the SSH key name that you provided, or you can make use of the terraform output to access the output value:
In this tutorial we will setup a python bot for our matrix chat server. We will only do a couple of basic commands, so that you have a solid base to build from.
Matrix Server
In our previous post we’ve setup a matrix and element server, so if you are following along, head over to that post to setup your matrix server before continuing.